AI 开发实战 - 如何成为 AI Native 软件工程师
〇、About
我不是 AI 领域专家,也不是做大模型或算法的。作为重度使用者。过去一个月,在日常工作中高强度使用 AI 编程工具,积累了一些实战经验。今天分享的所有案例都来自真实工作场景,正在跑的代码,正在解决的问题。
一、AI Coding 正在经历 “ChatGPT 时刻”
2022 年底 ChatGPT 发布时,所有人都意识到”对话式 AI”从实验室走进了日常生活。同样的事情,正在 AI Coding 领域发生。
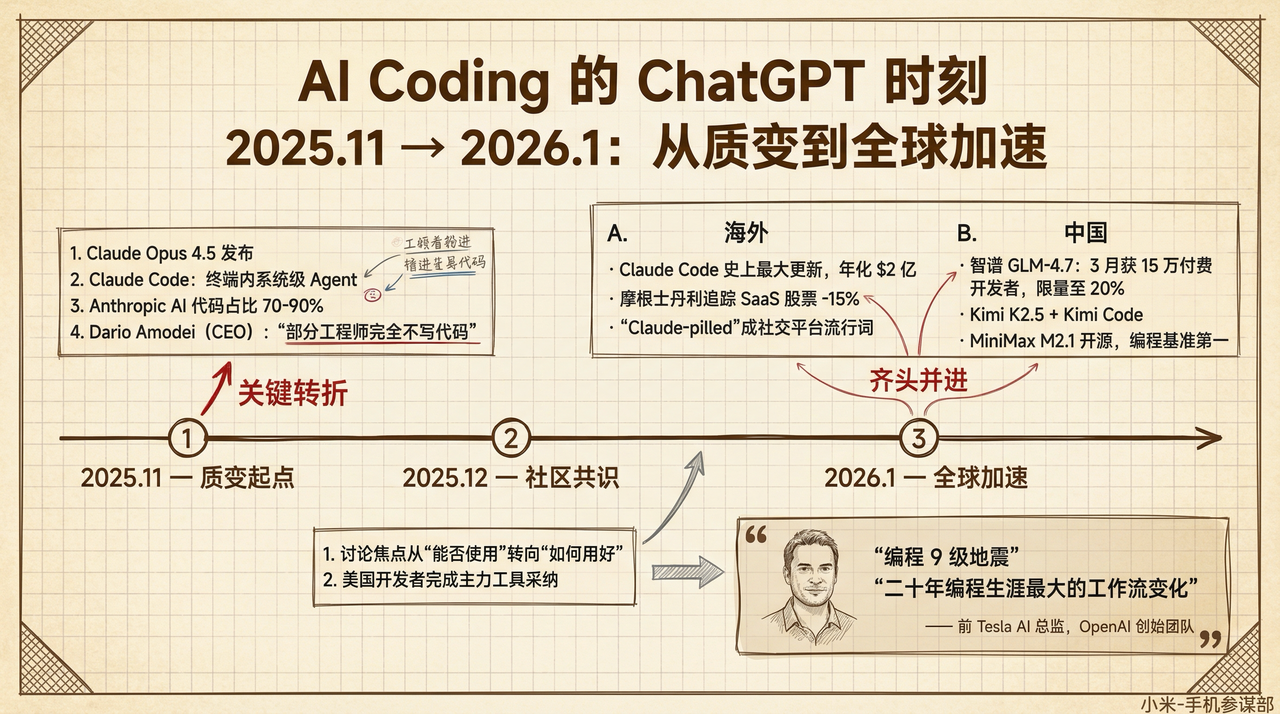
2025 年 12 月:美国开发者社区的集体转向
2025 年下半年,AI 编程工具经历了一次质变。11 月 24 日 Anthropic 发布 Claude Opus 4.5,编码能力大幅跃升。与此同时,Claude Code(运行在终端里的 AI 编程代理)开始被大量开发者采用——它能读懂整个项目、自主写代码、跑测试、修 bug——一个系统级 Agent。Anthropic 全公司 AI 生成代码占比 70%-90%,CEO Dario Amodei 在达沃斯论坛上说,公司内一些工程师已经完全不自己写代码了。到 12 月,美国开发者社区已经完成了从”尝鲜”到”主力工具”的转变。Twitter、Hacker News、各种技术博客上,关于 AI Coding 的讨论已经跳过了”能不能用”,直接进入”怎么用得更好”。
2026 年 1 月:中美齐头并进
海外这边,Claude Code 持续爆火,1 月发布史上最大版本更新,年化收入突破 2 亿美元,“Claude-pilled”(对 Claude 上瘾)成了社交平台流行词。摩根士丹利追踪的 SaaS 股票开年累计下跌 15%——华尔街开始认真对待 AI 编程对传统软件的冲击了。国内三家模型厂商同步发力:智谱 GLM-4.7 上线后 3 个月获超 15 万付费开发者,算力紧张到 1 月 23 日起限量发售,每日额度降为原来的 20%。Kimi 发布 K2.5,上线 Kimi Code 编程平台。MiniMax M2.1 开源后拿下编程基准开源模型第一。三家几乎同时 all in AI 编程,竞争烈度前所未有。Karpathy 的两次发声也在推波助澜。12 月底的年度回顾中他断言 vibe coding 将”重塑软件行业并改变岗位描述”;1 月底又分享个人转变——四周内从 80% 手写代码变成 80% 依赖 AI Agent,称这是”二十年编程生涯最大的工作流变化”。
为什么说这是 AI Coding 的 “ChatGPT 时刻”
ChatGPT 的意义是它让所有人意识到:自然语言交互已经可以解决真实问题了。AI Coding 的”ChatGPT 时刻”也是一样。之前的 AI 编程工具——Copilot、cursor、ChatGPT 辅助写代码——本质上是”更聪明的自动补全”。你仍然需要自己写大部分代码,AI 帮你补几行、写写模板。现在不一样了。当前这一代 AI 编程工具,能做到的是:
• 你告诉它”我要实现一个语音输入功能,支持实时流式识别,UI 要跟现有键盘风格统一”,它会自主读你的项目代码,理解架构,选择合适的技术方案,然后写出完整的实现
• 你给它一个 300 万行的 bugreport 日志,它能在几分钟内定位性能瓶颈的根因
• 你让它分析一个你不熟悉的代码库,它能跨三个仓库追踪调用链,找到问题根源
💡
开发者的角色变了——从”写代码的人”变成了”指挥 AI 写代码的人”。
二、实战:AI 能做到什么
以下三个案例都来自最近的实际工作。
案例 1:一天完成一个完整功能——小米输入法语音输入
Claude Code 实践(1) - 当天从零到生产级的输入法语音功能开发
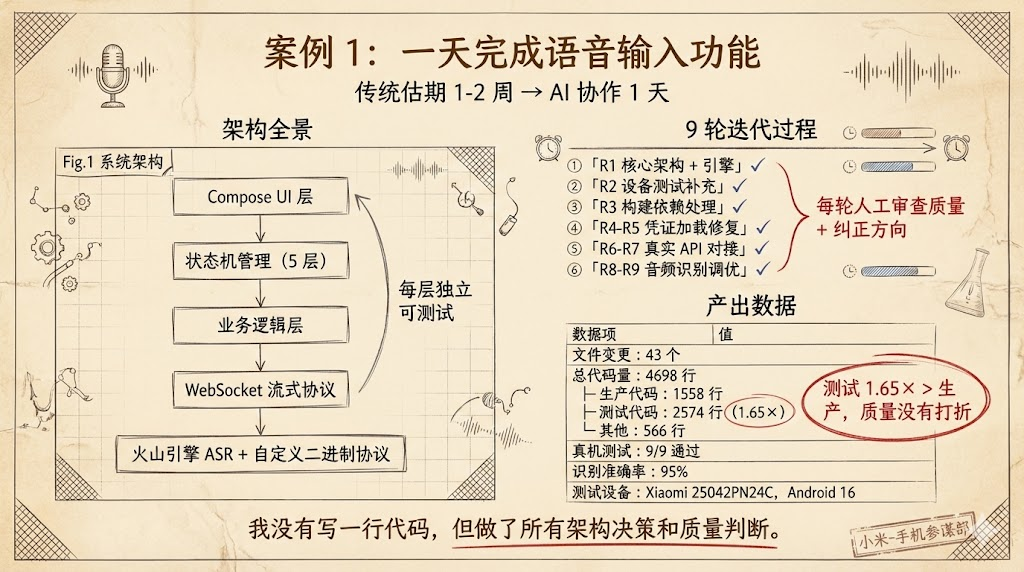
背景:我在做小米输入法项目(Jetpack Compose 架构),需要新增语音输入功能。这个功能涉及的技术栈——WebSocket 流式协议对接火山引擎 ASR、实时音频录制与编码、自定义二进制协议解析、Compose UI 交互、状态机管理。
如果按传统方式估期,一个熟悉 Android 和音频开发的工程师,至少需要 3-4 周。
过程:我用 Claude Code 协作开发。整个过程分成 9 轮迭代,每轮都有明确的目标:第一轮搭建核心架构和引擎实现;第二轮补充 Android 设备测试;第三轮处理构建依赖;后面几轮逐步修复凭证加载、真实 API 对接、实际音频识别等问题。
结果:
• 一天完成,43 个文件变更,新增 4698 行代码
• 其中生产代码 1558 行,测试代码 2574 行——测试代码是生产代码的 1.65 倍
• 真机测试 9 项全部通过
✅
关键不是”快”,是质量没有打折。4698 行代码不是 AI 一口气吐出来的”能跑就行”的东西。5 层状态机的架构,3 层测试防线(单元测试、设备测试、真实 API 测试),还有协议文档。9 轮迭代意味着每一轮我都在审查代码质量、验证功能正确性、纠正设计方向。
这是”AI 执行、人把关”的典型模式。我没有写一行代码,但我做了所有的架构决策和质量判断。
案例 2:15分钟从日志到OS源码级根因排查
Claude Code 实践(4) - 2轮修正,15分钟完成 OS 源码级问题根因排查
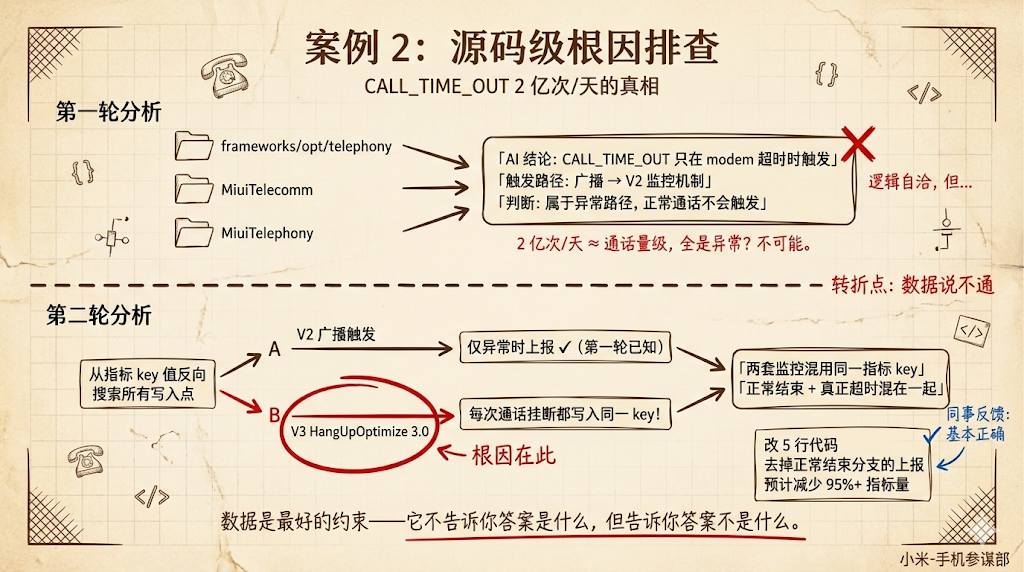
背景:有一个线上指标异常——CALL_TIME_OUT 事件每天触发 2 亿次。我需要找到根因,但我对 Telephony 这块代码不熟悉。涉及三个仓库:frameworks/opt/telephony、MiuiTelecomm、MiuiTelephony,加起来几万行代码。
**第一轮:**AI 给了一个”看起来对”的结论。我让 AI 阅读三个仓库的代码,追踪 CALL_TIME_OUT 的触发路径。几分钟后,AI 给出了分析:这个事件只在底层 modem 超时时触发,属于异常路径,正常通话不会触发。逻辑自洽,代码引用准确。
但数据说不通。2 亿次/天的量级跟用户通话量是对得上的——如果真的只在异常时触发,不可能有这么大的量。这说明 AI 的结论虽然局部正确,但遗漏了什么。
第二轮:加入数据约束后修正。我把”必须解释 2 亿次/天”作为约束条件重新提给 AI。这次 AI 改变了搜索策略——不再从广播名称正向追踪,而是从指标的 key 值反向搜索所有写入点。
结果发现了关键信息:这个系统里有两套并行的监控机制。V2 是广播触发的,确实只在异常时上报(第一轮找到的就是这个)。但还有一个 V3(HangUpOptimize 3.0),它在每次通话挂断时都会写入同一个指标 key——把”正常通话结束”和”真正的超时告警”混在了一起。
修复方案:改 5 行代码,把正常结束分支的上报去掉,预计减少 95% 以上的指标量。
我把分析结果发给负责这块的同事,反馈是”基本正确,至少会起到很大效果”。
传统方式:在不熟悉的代码库做这种跨仓库根因排查,资深工程师至少需要半天到一天。AI 协作 + 领域专家验证,两轮对话,大约 10 分钟。
🎁
但这个案例更重要的教训是:AI 第一轮给的结论是错的。它不是乱说——逻辑清晰,代码引用准确——但它遗漏了 V3 监控系统。如果我不带着数据质疑它,就会采纳一个”局部正确、全局遗漏”的结论。这说明人的判断力在 AI 协作中不可替代。数据是最好的约束——它不告诉你答案是什么,但告诉你答案不是什么。
案例 3:3 分 14 秒定位必现性能问题
Claude Code 实践(2) - 3分14秒实现必现性能问题从分析到修复建议
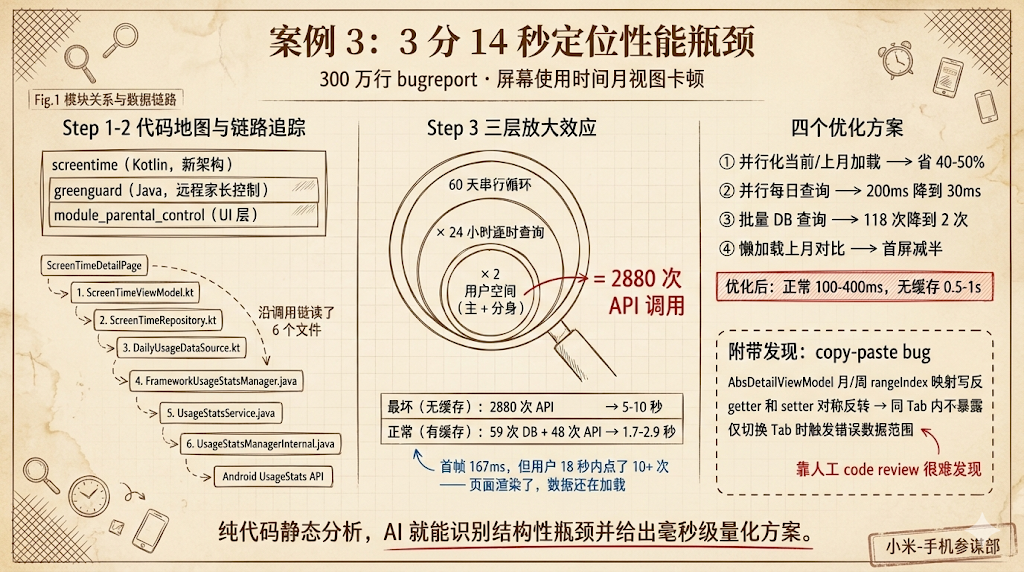
用链读了 6 个文件,追到最底层的 Android UsageStats API。
第三步,量化瓶颈:找到了根因。月视图需要加载最近 30 天 + 上月同期 30 天做对比,共 60 天数据。问题在于三层放大效应——
• 第一层:60 天串行循环,每天顺序处理,没有并行化
• 第二层:每天遍历 24 小时,逐小时查询系统 API 或缓存
• 第三层:双用户空间(主空间 + 分身空间)
最坏情况(首次打开,无缓存):60 × 24 × 2 = 2880 次系统 API 调用。正常情况(历史天有缓存,仅当天命中 API):59 次数据库查询 + 48 次 API 调用,耗时约 1.7-2.9 秒。
bugreport 也印证了这个分析:Activity 启动到首帧渲染只用了 167ms,但用户在之后的 18 秒里点了 10 多次——页面渲染了,数据还在加载。
AI 还顺手给出了四个优化方案和量化预期:并行化当前/上月加载(省 40-50%)、并行化每日查询(从 200ms 降到 30ms)、批量数据库查询(118 次查询降到 2 次)、懒加载上月对比数据(首屏时间减半)。综合优化后,正常场景从 1.7-2.9 秒降到 100-400ms,首次无缓存场景从 5-10 秒降到 0.5-1 秒。
最坏情况(首次打开,无缓存):60 × 24 × 2 = 2880 次系统 API 调用。正常情况(历史天有缓存,仅当天命中 API):59 次数据库查询 + 48 次 API 调用,耗时约 1.7-2.9 秒。
bugreport 也印证了这个分析:Activity 启动到首帧渲染只用了 167ms,但用户在之后的 18 秒里点了 10 多次——页面渲染了,数据还在加载。
AI 还顺手给出了四个优化方案和量化预期:并行化当前/上月加载(省 40-50%)、并行化每日查询(从 200ms 降到 30ms)、批量数据库查询(118 次查询降到 2 次)、懒加载上月对比数据(首屏时间减半)。综合优化后,正常场景从 1.7-2.9 秒降到 100-400ms,首次无缓存场景从 5-10 秒降到 0.5-1 秒。
附带发现:AI 在追踪代码时还发现了一个 copy-paste 错误——AbsDetailViewModel 里月和周的 rangeIndex 映射写反了。因为 getter 和 setter 对称地反了,同一 Tab 内不会出问题,只有切换 Tab 时才会触发错误数据范围,间接影响内存缓存命中率。这种 bug 靠人工 code review 很难发现。
总结:纯靠代码静态分析,AI 就能识别出”60 天串行循环 × 24 小时遍历”这种结构性瓶颈,并给出量化到毫秒级的优化方案。传统方式下,不熟悉代码库的工程师要做到同样的分析深度,至少需要数小时。
三、方法论:怎么做到的
模型能力是基础,但要在真实工作中发挥出来,需要一套方法。先讲具体工具怎么用,再讲背后的思维转变。
具体方法:Claude Code 的核心机制
Claude Code in Action:如何用 Skills、MCP、CLAUDE.md 和 Subagents 构建工作流
Claude Code 2.0 指南:如何更好地使用编码 Agent
Anthropic:为 AI Agent 写好工具 - 用 AI Agent 来写
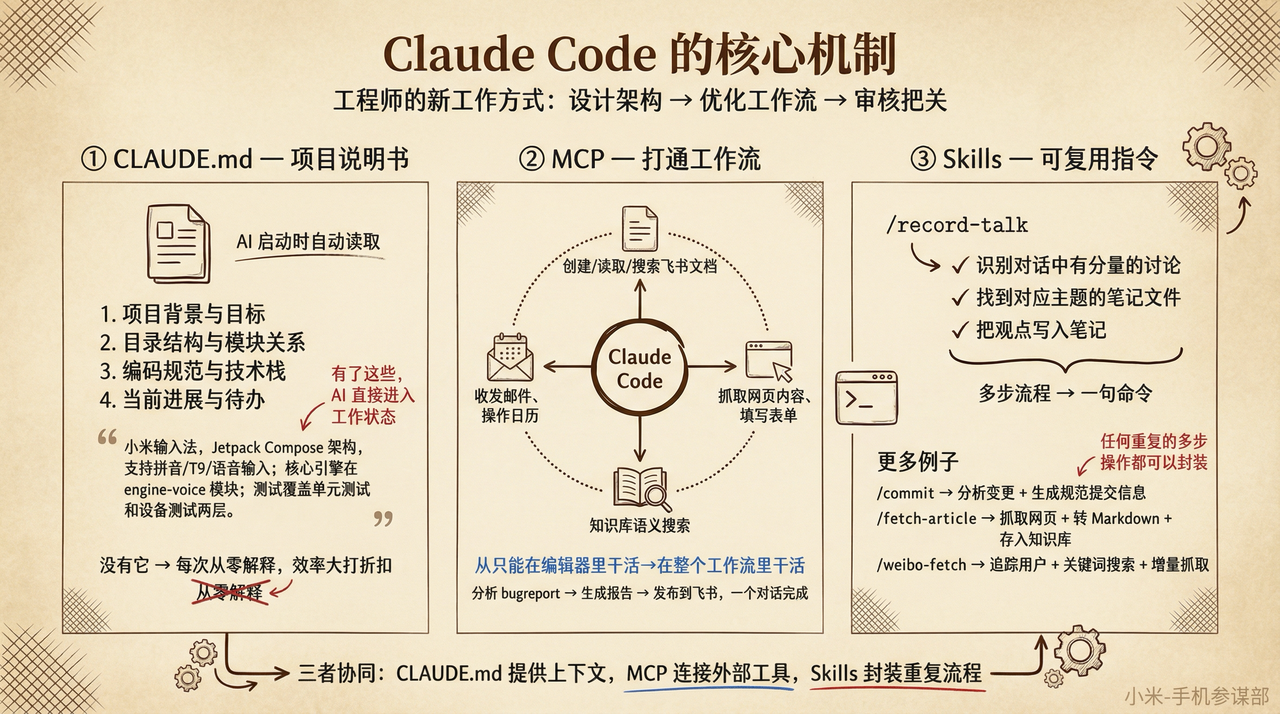
先说使用方式的根本变化。用 Claude Code 写代码,工程师不再一行一行敲——你的工作变成了两件事:设计架构和规格,然后审核把关。中间怎么让 AI 跑得更快更准,是持续优化的过程,不是一个独立步骤。写代码本身不再是关键能力,和 AI 协作把效率拉到 10 倍,才是关键。
这套工作方式能跑通,靠的是 Claude Code 的几个核心机制:
CLAUDE.md——项目说明书
Claude Code 在每次启动时会自动读取项目根目录的 CLAUDE.md 文件。这个文件的作用相当于”项目说明书”——告诉 AI 这个项目的背景、目标、目录结构、编码规范、技术栈、当前进展。
举个例子,我的小米输入法项目的 CLAUDE.md 里写了:这是一个 Jetpack Compose 架构的输入法,支持拼音、T9、语音输入;核心引擎在 engine-voice 模块里;测试要覆盖单元测试和设备测试两层。有了这些上下文,AI 写出来的代码天然就会遵循项目的架构和规范,而不是每次都要从零解释。
这是一个看起来简单但效果巨大的机制。没有它,你每次跟 AI 对话都要重新描述项目背景,效率大打折扣。有了它,AI 就像一个”读过所有文档的新同事”,直接进入工作状态。
MCP 工具集成——打通工作流
MCP(Model Context Protocol)是让 AI Agent 调用外部工具的标准协议。简单说,装了 MCP 插件的 Claude Code,不只能读写本地文件,还能:
• 直接操作飞书:创建文档、读取文档、搜索信息
• 控制浏览器:抓取网页内容、填写表单
• 查询知识库:在你积累的资料库中做语义搜索
• 收发邮件、操作日历……
举个场景:我让 AI 分析完 bugreport 后,直接发布分析报告到飞书文档。分析日志、生成报告、发布到飞书,整个流程在一个对话里完成,不用在工具之间来回切换。
MCP 的意义在于:它让 AI 从”只能在代码编辑器里干活”变成了”能在你的整个工作流里干活”。
Skills——可复用的指令
如果某类任务你经常做,可以把它封装成一个 Skill。比如我封装了一个 /record-talk 命令——它的作用是在对话结束时,自动识别有分量的讨论内容,找到对应的笔记文件,把观点写进去。
这相当于把”判断讨论价值 → 找到正确文件 → 写入笔记”这个多步流程,变成了一句命令。类似的,你可以封装代码审查流程、发布流程、日志分析流程——任何重复的多步操作,都可以变成一个 Skill。
更高层的认知转变
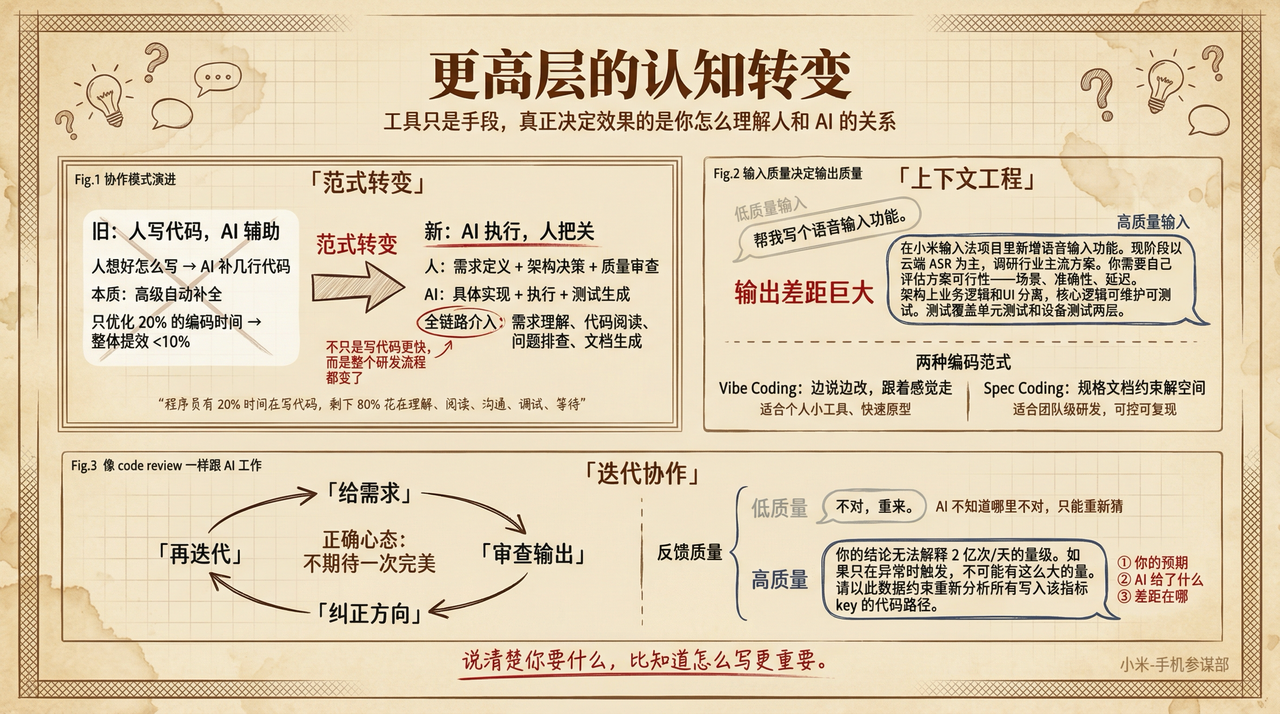
工具只是手段。真正决定效果的,是你怎么理解人和 AI 的关系。
先纠正一个常见误解:AI 提效 = 写代码更快。但程序员只有 20% 的时间在写代码,剩下 80% 花在理解需求、阅读文档、沟通对齐、调试排查、等待 review、部署发布。如果 AI 只是让那 20% 快了 100%,整体效能提升不到 10%。真正的提效是全链路的——需求理解、代码阅读、问题排查、文档生成,这些 AI 都能介入,前面的三个案例已经证明了这一点。
从”人写代码、AI 辅助”到”AI 执行、人把关”
很多人用 AI 编程的方式是:自己想好怎么写,让 AI 帮忙补几行代码、生成一些模板。这是把 AI 当”高级自动补全”用——只优化了那 20%,提效有限。
更高效的方式是反过来——你负责需求定义、架构决策和质量审查,AI 负责具体实现。回顾语音输入的案例:我没有写一行代码,但我做了所有关键决策——选择 WebSocket 流式架构、确定 5 层状态机设计、要求完整的单元测试、集成测试。AI 把这些决策变成了 4698 行可运行的代码。
说白了就是分工。现阶段人擅长判断”想做什么”和”做得好不好”,AI 擅长”怎么做”和”做得快”。
上下文工程:说清楚你要什么,比知道怎么写更重要
Anthropic:如何实现高效的上下文工程
一句话说得很好”世界上几乎没有不可分析的问题,只有上下文不足的问题。“这句话放在 AI 协作中同样成立——AI 的输出质量,很大程度上取决于你给它的上下文质量。同一个模型,给模糊的需求和给精确的 Spec,输出的差距是巨大的。
低质量输入:“帮我写个语音输入功能。”
高质量输入:“在小米输入法项目里新增语音输入功能。现阶段以云端 ASR 为主,调研行业主流方案,你需要自己评估方案的可行性——场景是否满足、识别准确性、延迟表现。架构上业务逻辑和 UI 分离,核心逻辑要可维护可测试。测试覆盖单元测试和设备测试两层。”
两者的输出质量完全不同。后者不需要你知道每行代码怎么写,但需要你清晰地定义你要什么。这是”上下文工程”的核心——你在管理 AI 的输入信息,确保它有足够的约束来生成高质量的输出。
这里延伸一个概念:业界把”边说边改、跟着感觉走”的方式叫 Vibe Coding,个人做小工具、快速原型很好用。但团队级研发需要的是 Spec Coding——用规格文档约束 AI 的解空间,把大问题拆成小的正交子任务,让 AI 的行为可控、可复现、可审计。前面语音输入的高质量输入示例,本质上就是 Spec Coding 的思路。
迭代协作:像 code review 一样跟 AI 工作
不要期待 AI 一次就给出完美答案。正确的心态是:给需求 → 审查输出 → 纠正方向 → 再迭代。跟做 code review 一样——你不会因为一个 PR 有问题就否定整个方案,你会指出问题让对方改。
Telephony 的案例就是典型:第一轮 AI 给了一个”看起来对但实际有遗漏”的结论。我没有放弃,也没有全盘接受,而是用数据约束它重新分析。第二轮就找到了真正的根因。
好的反馈是高效迭代的关键。低质量反馈:“不对,重来。“AI 不知道哪里不对,只能重新猜。高质量反馈:“你的结论无法解释 2 亿次/天的量级。如果只在异常时触发,不可能有这么大的量。请以这个数据约束重新分析所有写入该指标 key 的代码路径。“高质量反馈包含三个要素:你的预期是什么,AI 给的是什么,差距在哪里。
四、AI 的局限与使用规则
高强度使用下来,对 AI 能做什么、不能做什么,有了些认知。
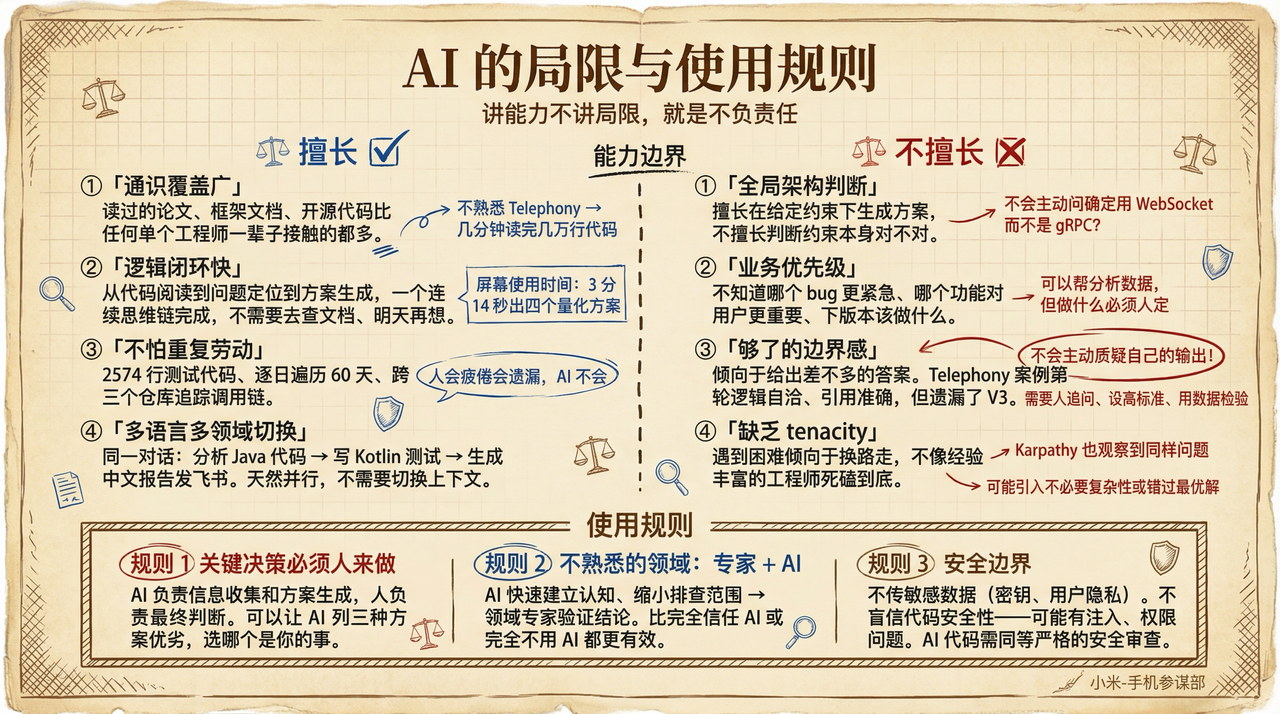
AI 擅长什么
AI 的优势首先在通识覆盖广。一个 Opus 级别的模型,读过的论文、框架文档、开源代码,比任何单个工程师一辈子接触的都多。当你需要在不熟悉的领域快速建立认知——比如我对 Telephony 代码不熟悉——AI 可以在几分钟内帮你读完几万行代码并给出结构化的理解。同时逻辑闭环快,从代码阅读到问题定位到方案生成,可以在一个连续的思维链里完成,不需要”回去查一下文档""明天再想想”。屏幕使用时间的案例,从打开 bugreport 到给出四个量化优化方案,3 分 14 秒。在执行层面,AI 不怕重复劳动——写 2574 行测试代码、逐日遍历 60 天的数据加载逻辑、跨三个仓库追踪调用链,这些对人来说枯燥且容易出错的工作,AI 不会疲倦。而且多语言多领域切换自如,同一个对话里可以先分析 Java 代码,再写 Kotlin 测试,再生成一份中文分析报告发到飞书,不需要”切换上下文”。
AI 不擅长什么
首先是全局架构判断。AI 擅长在给定约束下生成方案,但不擅长判断”这个约束本身对不对”。它不会主动质疑:“你确定要用 WebSocket 而不是 gRPC 吗?“架构层面的取舍——性能 vs 可维护性、短期 vs 长期——仍然需要人来判断。类似地,业务优先级也不是 AI 能替你决定的。哪个 bug 优先级更高、哪个功能对用户更重要、下个版本该做什么——它可以帮你分析数据,但”做什么”的决策必须是人的。更微妙的问题是 AI 缺乏”够了”的边界感。Telephony 案例中,第一轮分析逻辑自洽、代码引用准确,如果我不用数据去质疑它,它不会主动说”我可能遗漏了什么”。AI 不会主动质疑自己的输出。需要人去追问、去设置更高的标准、去用数据检验结论。Karpathy 观察到一个相关的问题——AI 缺乏 tenacity,遇到困难时倾向于放弃当前方案、换一条路走,而不是像经验丰富的工程师那样坚持深挖。人类工程师知道”这条路应该走得通,一定是哪里出了问题”,会死磕到底;AI 更容易绕道而行,结果可能引入不必要的复杂性或错过最优解。
使用规则
基于这些认知,总结几条使用规则:
关键决策必须人来做。AI 负责信息收集和方案生成,人负责最终判断。你可以让 AI 列出三种技术方案的优劣,但选哪个、承担什么后果,是你的事。
不熟悉的领域,专家 + AI 配合。Telephony 的案例说明,在你不熟悉的领域,AI 可以帮你快速建立认知、缩小排查范围,但最终结论需要领域专家来验证。“AI 辅助 + 专家确认”的组合,远比”完全信任 AI”或”完全不用 AI”更有效。
安全边界。不要向 AI 传递敏感数据(密钥、用户隐私信息)。不要盲信 AI 生成代码的安全性——它可能引入注入漏洞、权限问题等。AI 生成的代码需要经过跟人写的代码同样严格的安全审查。
五、这意味着什么
Karpathy 的判断:编程 9 级地震
Karpathy 在 X 上的 AI 编程随笔 - 关于 Claude Code(26.01.27)
Andrej Karpathy——前 Tesla AI 总监、OpenAI 创始团队成员——用”9 级地震”来形容当前编程行业正在经历的变化。他列出了一串新概念:agents、subagents、prompts、contexts、memory、modes、permissions、tools、plugins、skills、hooks、MCP、slash commands……这些不是某个工具的功能列表,而是一套全新的编程范式的基本词汇。就像从汇编到高级语言需要建立新的心智模型一样,从传统编程到 AI 协作编程,我们也需要建立新的心智模型。传统工程实践正在被重新定义:代码覆盖率还有意义吗?单元测试怎么写?版本管理管的是代码还是 prompt?这些问题目前没有标准答案,但问题本身的存在就说明——范式在变。
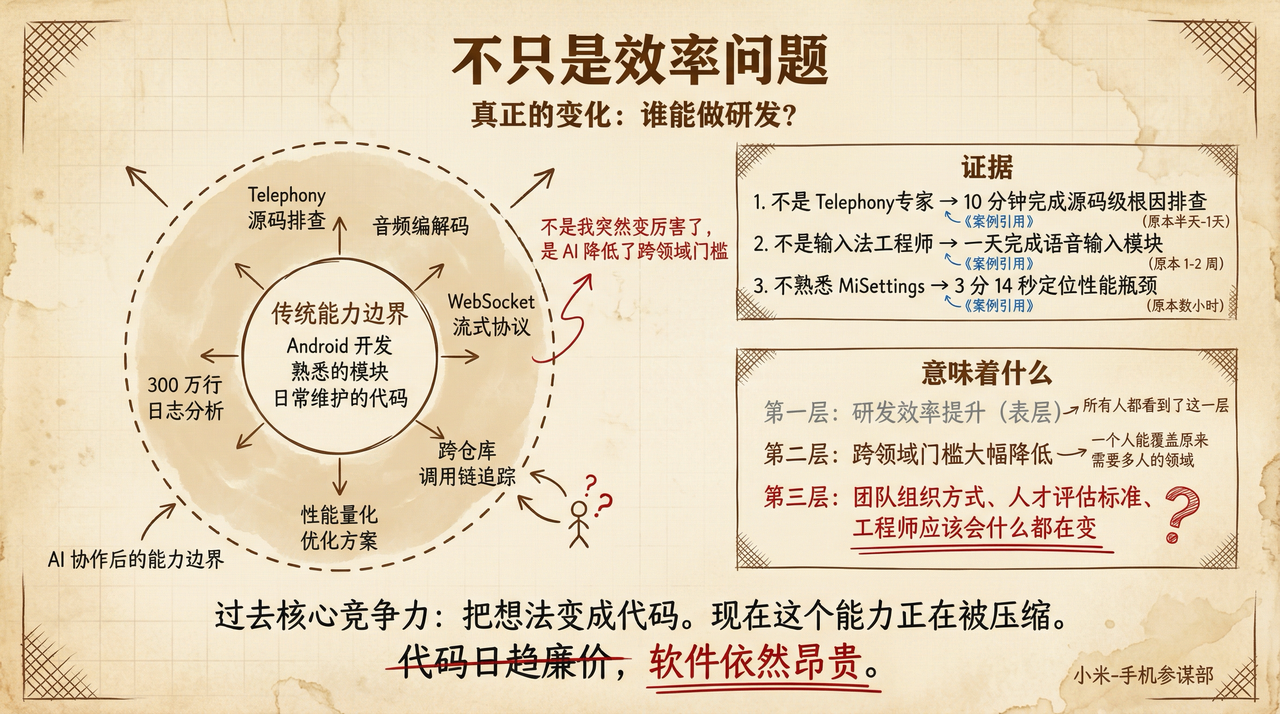
不只是效率问题
很多人把 AI Coding 理解为”效率翻倍”——同样的活干得更快了。这只是最表面的一层。更深的变化是:谁能做研发?我不是 Telephony 专家,但我能在 10 分钟内完成源码级的根因排查。我不是输入法开发工程师,但我能在一天内完成一个完整的语音输入模块。这不是因为我突然变厉害了,而是 AI 大幅降低了跨领域工作的门槛。这意味着研发团队的组织方式、人才评估标准、甚至”一个工程师应该会什么”这个问题的答案,都在发生变化。过去,一个工程师的核心竞争力是”把想法变成代码的能力”。现在,这个能力的价值正在被压缩——AI 能替代大部分实现工作。但”决定做什么”——判断哪个功能值得做、哪个架构方向正确、哪个技术风险可以接受、哪些需要极力避免——这些能力的价值反而在上升。
💡
代码在变便宜,但判断力没有。
对我们的启示
变化已经在发生了。我的建议是:尽早建立个人实践。不要等公司统一培训、等标准流程出来——那些需要时间。现在就可以做的事情:
• 在你手上的某个任务中试用 AI 编程工具(部门已经提供多套能力,特别是 claude code)
• 从小任务开始,逐步建立自己的使用习惯和判断力
• 关注自己的工作流里有哪些”每次都要重复解释”的环节——那些就是上下文工程的切入点
• 记录你的经验,包括成功的和失败的——这些会成为你的竞争力。我们OS的代码库有几千万行,日常工作中大量的日志分析、问题排查、跨模块代码理解,正是 AI 最能发挥的场景——前面的三个案例已经证明了这一点。越早开始用,越早知道哪些场景真的有效。