Android Perfetto 系列 07 - MainThread 和 RenderThread 解读
随着 Google 正式推出 Perfetto 工具替代 Systrace,Perfetto 在性能分析领域已经成为主流选择。本文将结合 Perfetto 的具体 trace 信息,帮助读者理解 MainThread 和 RenderThread 的完整工作流程,让你在使用 Perfetto 分析性能问题时能够:
- 准确识别关键 trace tag:知道 UI Thread、RenderThread 等关键线程的作用
- 理解帧渲染的完整流程:从 Vsync 信号到屏幕显示的每个步骤
- 定位性能瓶颈:通过 trace 信息快速找到卡顿和性能问题的根因
系列文章目录
- Android Perfetto 系列目录
- Android Perfetto 系列 1:Perfetto 工具简介
- Android Perfetto 系列 2:Perfetto Trace 抓取
- Android Perfetto 系列 3:熟悉 Perfetto View
- Android Perfetto 系列 4:使用命令行在本地打开超大 Trace
- Android Perfetto 系列 5:Android App 基于 Choreographer 的渲染流程
- Android Perfetto 系列 6:为什么是 120Hz?高刷新率的优势与挑战
- Android Perfetto 系列 7 - MainThread 和 RenderThread 解读
- Android Perfetto 系列 8:深入理解 Vsync 机制与性能分析
- 视频(B站) - Android Perfetto 基础和案例分享
如果大家还没看过 Systrace 系列,下面是传送门:
- Systrace 系列目录 : 系统介绍了 Perfetto 的前身 Systrace 的使用,并通过 Systrace 来学习和了解 Android 性能优化和 Android 系统运行的基本规则。
- 个人博客 :个人博客,主要是 Android 相关的内容,也放了一些生活和工作相关的内容。
欢迎大家在 关于我 页面加入微信群或者星球,讨论你的问题、你最想看到的关于 Perfetto 的部分,以及跟各位群友讨论所有 Android 开发相关的内容.
本文使用到的 Trace 文件我上传到了 Github :https://github.com/Gracker/SystraceForBlog/tree/master/Android_Perfetto/demo_app_aosp_scroll.perfetto-trace ,需要的可以自取。
注:本文内容基于 Android 16 的最新渲染架构
App 端的 QueuedBuffer 指标
BlastBufferQueue 的工作原理
BlastBufferQueue 是现代 Android 渲染架构中的关键组件,它改变了传统的缓冲区管理方式:
传统 BufferQueue vs BlastBufferQueue:
- 创建主体不同:
- 传统 BufferQueue:由 SurfaceFlinger 创建和管理
- BlastBufferQueue:由 App 端(ViewRootImpl)创建和管理
- 缓冲区获取机制:
- 传统方式:RenderThread 需要通过 Binder 调用向 SurfaceFlinger 请求 Buffer,可能会因为没有可用 Buffer 而阻塞
- BlastBufferQueue:App 端预先管理缓冲区池,RenderThread 可以更高效地获取 Buffer
- 提交机制:
- 传统方式:通过 queueBuffer 直接提交给 SurfaceFlinger
- BlastBufferQueue:通过 transaction 机制批量提交,减少 Binder 调用开销
在 Perfetto 中观察 BlastBufferQueue:
在 Perfetto 跟踪中,BlastBufferQueue 的状态通过以下关键指标显示:
App 端的 QueuedBuffer 指标
- Perfetto 显示:
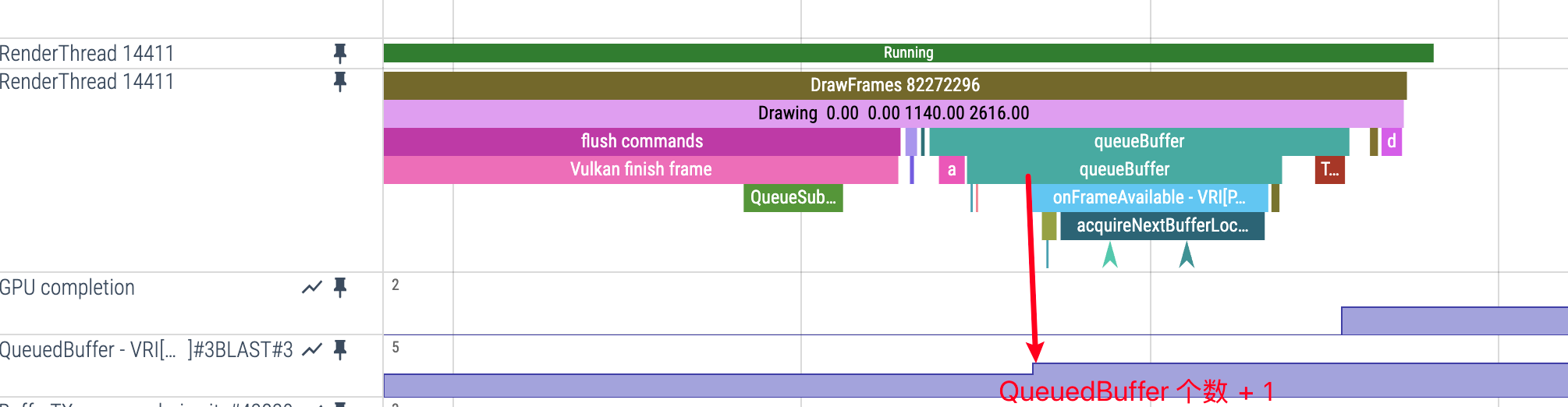
QueuedBuffer数值轨道 - 计算规则:App 生产的 Buffer 总数 = QueuedBuffer - 1
- 基准值说明:QueuedBuffer 的最小值为 1,0 表示没有 Buffer 在队列中
- 数值含义:QueuedBuffer 为 2 表示有 1 个 Buffer 在队列中,QueuedBuffer 为 3 表示有 2 个 Buffer 在队列中,以此类推

QueuedBuffer 数值变化时机
QueuedBuffer +1 的时机:
- 触发条件:RenderThread 执行
queueBuffer操作 - Perfetto 表现:
queueBuffer事件执行时,QueuedBuffer 计数增加 - 含义:RenderThread 将渲染完成的 Buffer 提交到 App 端的 BlastBufferQueue 中等待发送给 SurfaceFlinger
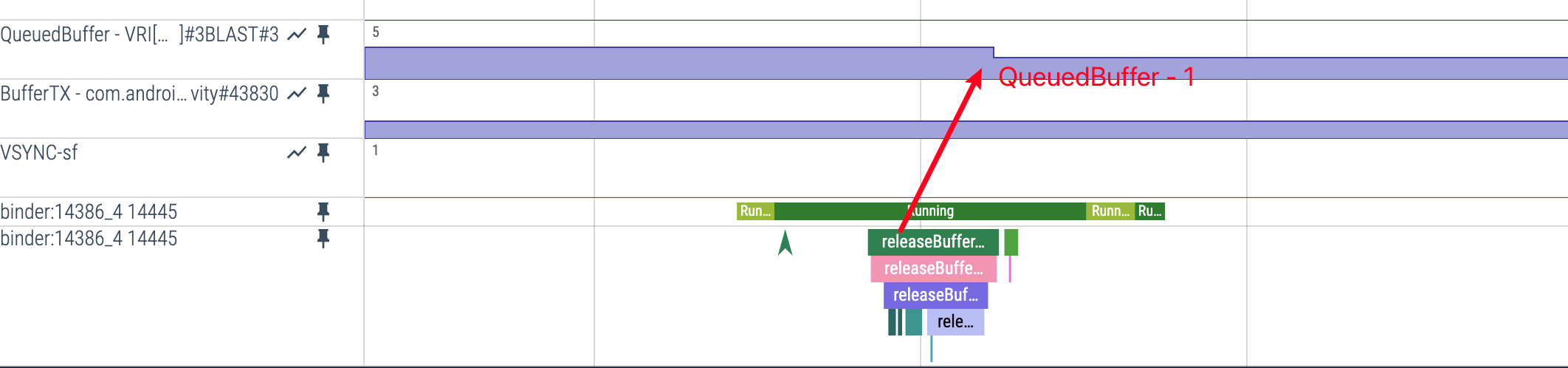
QueuedBuffer -1 的时机:
- 触发条件:收到 SurfaceFlinger 的
releaseBufferCallback - Perfetto 表现:可观察到
releaseBuffer相关事件 - 含义:SurfaceFlinger 已使用完某个 Buffer,将其释放回 App 端 BlastBufferQueue,该 Buffer 可重新用于渲染
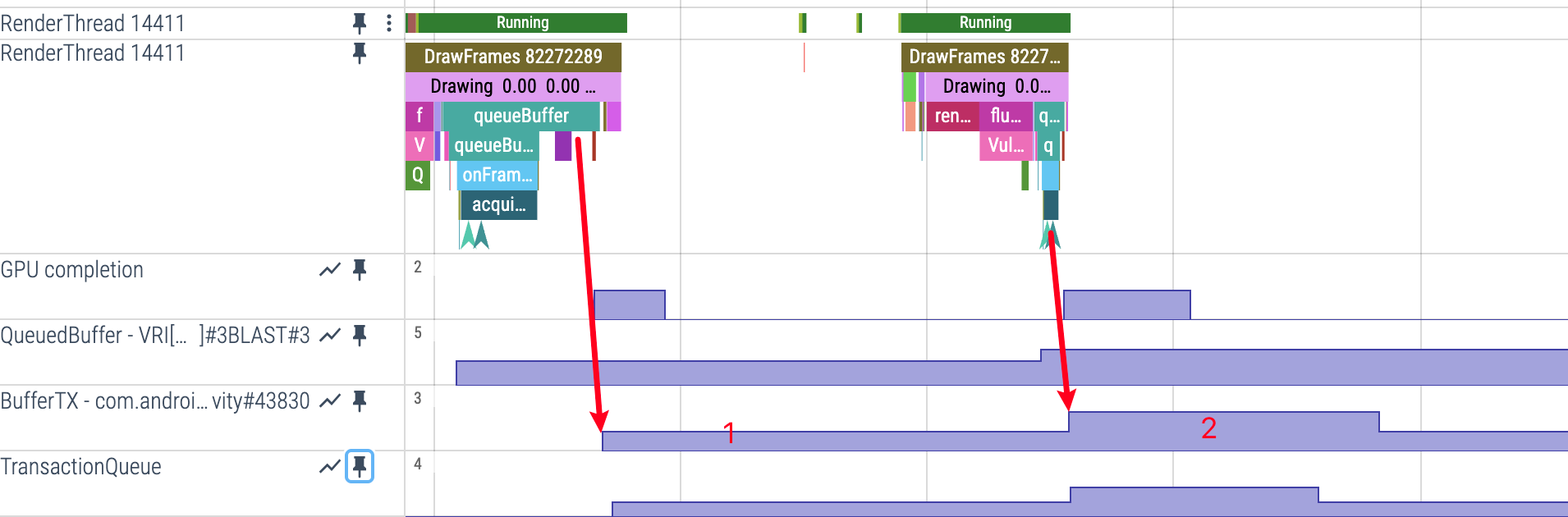
SurfaceFlinger 端的 BufferTX 指标
- Perfetto 显示:SurfaceFlinger 进程中的
BufferTX数值轨道 - 变化时机:SurfaceFlinger 接收到 Transaction 后 BufferTX +1
- 触发条件:App 端通过
flushTransaction将 Buffer 真正发送给 SurfaceFlinger - 最大值限制:BufferTX 最高为 3
- 原因说明:这个最大值为 3 的限制,实际上就是我们熟知的**三缓冲(Triple Buffering)**机制在合成侧的体现:一个正在被显示器读取(Front Buffer),一个准备在下一个 Vsync 周期被合成(Back Buffer),还有一个作为备用(Third Buffer)。这确保了即使在轻微的渲染抖动下,SurfaceFlinger 依然有帧可合成,从而提升流畅度
App 端和 SF 端的协作流程
- App 端:RenderThread
queueBuffer→ App 端 QueuedBuffer +1(Buffer 进入 App 端队列) - App 端:
flushTransaction→ 将队列中的 Buffer 批量发送给 SurfaceFlinger - SF 端:接收 Transaction → SF 端 BufferTX +1(Buffer 进入 SF 端处理)
- SF 端:处理完成后发送
releaseBufferCallback→ App 端 QueuedBuffer -1(Buffer 释放回 App)
关键性能观察点
在分析性能时,重点关注:
- App 端 QueuedBuffer 数值:反映渲染生产速度,如果 App 生产过慢,QueuedBuffer 个数就可以反应出来 (always 是 1 ,说明没有 Buffer 生产出来)。重点关注需要连续出帧的场景(比如滑动过程),QueuedBuffer 的值为 1 超过 1 个 Vsync 的地方,看对应的 App 主线程和渲染线程是否有性能问题。
- SurfaceFlinger 端 BufferTX:反映系统合成处理能力 ,如果 SurfaceFlinger 消费 Buffer 过慢,也会有性能问题。重点关注需要连续出帧的场景(比如滑动过程) ,对应的 BufferTX 为 0 的情况 或者 BufferTX 没有被消费的情况,前一种情况是 App 的问题,后一种情况是 SurfaceFlinger 的问题。
性能
如果主线程需要处理所有任务,则执行耗时较长的操作(例如,网络访问或数据库查询)将会阻塞整个界面线程。一旦被阻塞,线程将无法分派任何事件,包括绘图事件。主线程执行超时通常会带来两个问题
- 卡顿:如果主线程 + 渲染线程每一帧的执行都超过 8.33ms(120fps 的情况下),那么就可能会出现掉帧(说可能是因为有的情况下其实不会掉帧,因为有 app duration 、buffer 堆积等情况)。
- 卡死:如果界面线程被阻塞超过几秒钟时间(根据组件不同 , 这里的阈值也不同),用户会看到 “应用无响应“ (ANR) 对话框(部分厂商屏蔽了这个弹框,会直接 Crash 到桌面)
对于用户来说,这两个情况都是用户不愿意看到的,所以对于 App 开发者来说,两个问题是发版本之前必须要解决的,ANR 这个由于有详细的调用栈,所以相对来说比较好定位;但是间歇性卡顿这个,可能就需要使用工具来进行分析了:Perfetto + Trace View (Android Studio 已经集成),所以理解主线程和渲染线程的关系和他们的工作原理是非常重要的,这也是本系列的一个初衷。
Perfetto 独有的 FrameTimeline 功能
Perfetto 相比 Systrace 的一个重要优势是提供了 FrameTimeline 功能,可以一眼就可以看到卡顿的地方。
注意: FrameTimeline 需要 Android 12(S) 或更高版本支持
FrameTimeline 的核心概念
根据 Perfetto 官方文档,当帧在屏幕上的实际呈现时间与调度器预期的呈现时间不匹配时,就会产生卡顿。FrameTimeline 为每个有帧在屏幕上显示的应用添加了两个新的轨道:

1. Expected Timeline(预期时间线)
- 作用: 显示系统分配给应用的渲染时间窗口
- 开始时间: Choreographer 回调被调度运行的时间
- 含义: 为了避免系统卡顿,应用需要在这个时间范围内完成工作
2. Actual Timeline(实际时间线)
- 作用: 显示应用完成帧的实际时间(包括 GPU 工作)
- 开始时间:
Choreographer#doFrame或AChoreographer_vsyncCallback开始运行的时间 - 结束时间:
max(GPU 时间, Post 时间),其中 Post 时间是帧被提交到 SurfaceFlinger 的时间
当你点击 Actual Timeline 上的一个 追踪的时候,会显示这一帧具体的被消费的时间(可以看延时)。
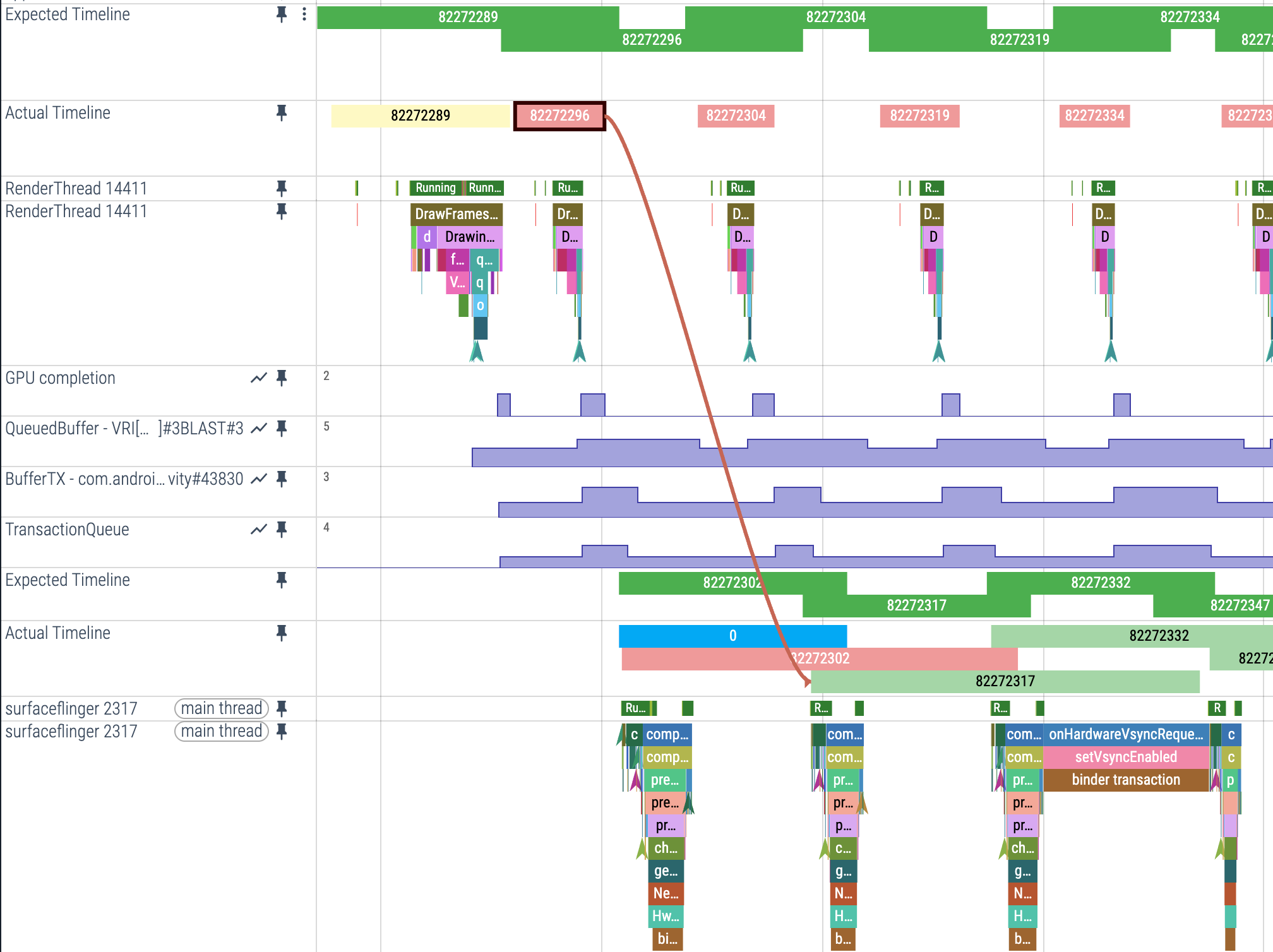
上面这个点很好,可以支撑流畅度归因工具,buffer生产和buffert消费对应关系
颜色编码系统
FrameTimeline 使用直观的颜色来标识不同的帧状态:
| 颜色 | 含义 | 说明 |
|---|---|---|
| 绿色 | 正常帧 | 没有观察到卡顿,理想状态 |
| 浅绿色 | 高延迟状态 | 帧率稳定但帧呈现延迟,导致输入延迟增加 |
| 红色 | 卡顿帧 | 当前进程导致的卡顿 |
| 黄色 | 应用无责任卡顿 | 帧出现卡顿但应用不是原因,SurfaceFlinger 导致的卡顿 |
| 蓝色 | 丢帧 | SurfaceFlinger 丢弃了该帧,选择了更新的帧 |
点击不同颜色的 ActualTimeline 可以在信息栏看到下面的描述,告诉你卡顿的原因:
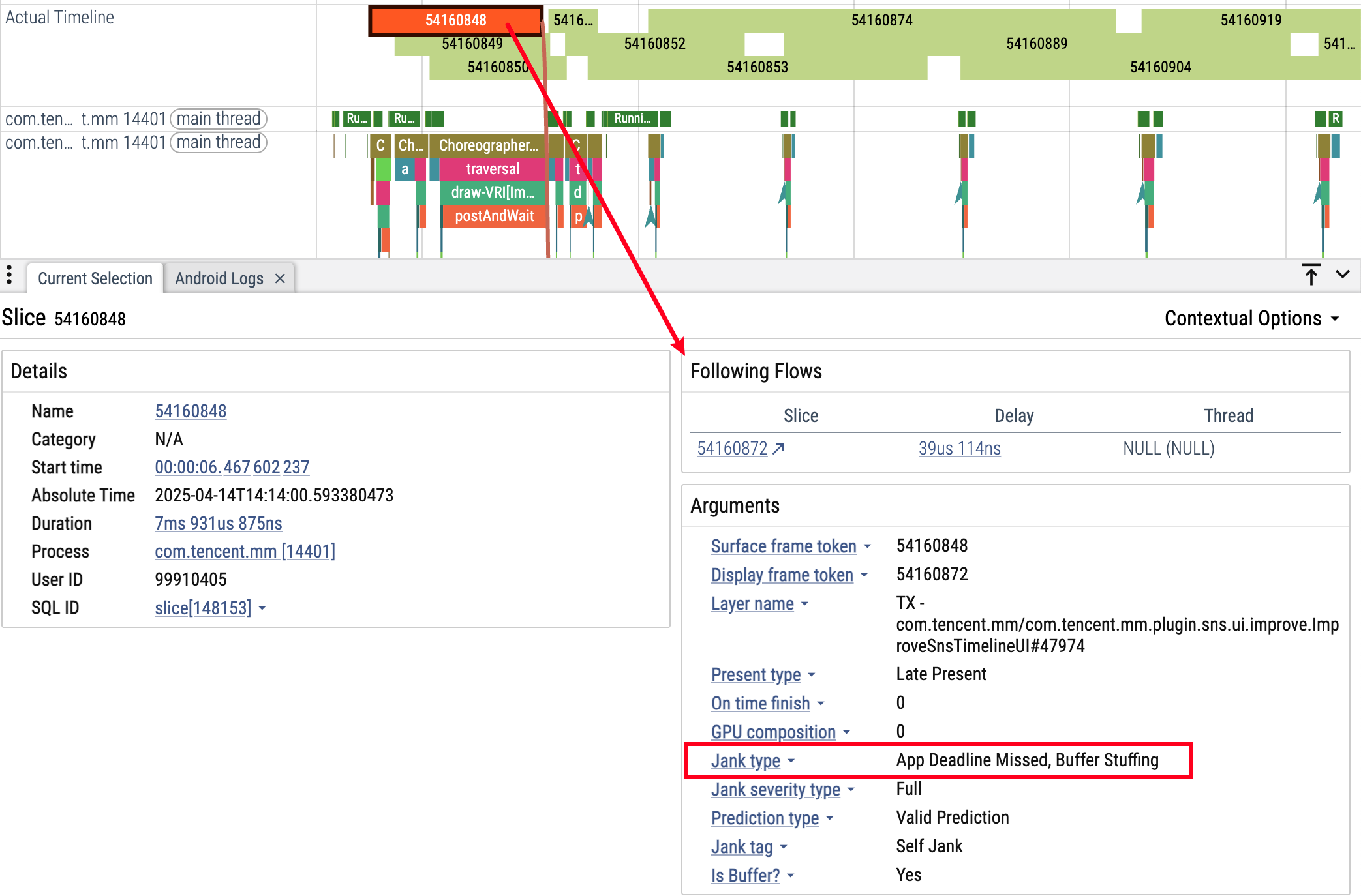
卡顿类型分析
FrameTimeline 可以识别多种卡顿类型:
应用端卡顿:
- AppDeadlineMissed: 应用运行时间超过预期
- BufferStuffing: 应用在前一帧呈现前就发送新帧,导致 Buffer 队列堆积
SurfaceFlinger 卡顿:
- SurfaceFlingerCpuDeadlineMissed: SurfaceFlinger 主线程超时
- SurfaceFlingerGpuDeadlineMissed: GPU 合成时间超时
- DisplayHAL: HAL 层呈现延迟
- PredictionError: 调度器预测偏差
配置 FrameTimeline
在 Perfetto 配置中启用 FrameTimeline
data_sources {
config {
name: "android.surfaceflinger.frametimeline"
}
}Perfetto 中 Vsync 信号
在 Perfetto 中,Vsync 信号使用 Counter 类型来显示,这与很多人的直觉认知不同:
- 0 → 1 的变化:表示一个 Vsync 信号
- 1 → 0 的变化:同样表示一个 Vsync 信号
- 错误理解:很多人误以为只有变成 1 才是 Vsync 信号
正确的 Vsync 信号识别
下图中 1 、2、3、4 的时间点都是 Vsync 信号到达

关键要点:
- 每次数值变化都是一个 Vsync:无论是 0→1 还是 1→0
- 信号频率:120Hz 设备上约每 8.33ms 会有一次变化(实际可能因系统调度略有差异,这里指的是连续出帧场景)
- 多 App 场景:Counter 可能因为其他 App 的申请而保持活跃状态
分析技巧
判断 App 是否接收到 Vsync:
- 正确方法:查看 App 进程中是否有对应的
FrameDisplayEventReceiver.onVsync事件 - 错误方法:仅凭 SurfaceFlinger 中的
vsync-appcounter 变化来判断