RenderThread耗时如何定位是哪个View
背景
Render thread线程,也就是RT线程,在systrace中经常出现绘制耗时导致丢帧卡顿的问题,此时需要定位是上层的哪个View导致的。但是RT线程默认的trace信息很少,根据默认的trace难以直接定位是哪个View在耗时。因此本文总结定位RT线程耗时对应View的方法。
RT线程流程简介
如图是一个常见的rt线程的trace:

这里有几个重要的阶段:
syncFrameState:这里是和UI线程同步信息。
beginFrame:主要是在dequeueBuffer,一般dequeueBuffer耗时长可能是sf丢帧导致。
renderFrame:遍历由View树绘制得到的RenderNode树,并创建用来绘制的RenderTask和Op。
flush commads:执行RenderTask和Op进行绘制操作。
eglSwapBuffersWithDamageKHR:主要是在queueBuffer,这里有时候会有waitForever耗时问题,一般是gpu绘制超时导致的。
本文接下来重点分析和View绘制相关的renderFrame和flush commands阶段。
RenderFrame阶段
在UI线程View执行draw操作的时候,每个View会创建一个RenderNode。一般来说一个View对应一个RenderNode,实际上在View的onDraw方法里面可以自己创建RenderNode,达到一个View对应多个RenderNode的情况。
到了RT线程的RenderFrame阶段,这些RenderNode会被装进RenderNodeDrawable对象中,递归遍历这个RenderNodeDrawable组成的树。
因此我们只要在RenderNodeDrawable::drawContent方法中打印出当前的RenderNode名字:(frameworks/base/libs/hwui/pipeline/skia/RenderNodeDrawable.cpp)
void RenderNodeDrawable::drawContent(SkCanvas* canvas) const {
RenderNode* renderNode = mRenderNode.get();
ATRACE_FORMAT("%s", renderNode->getName()); // 打印RenderNode的名字
...
}就可以知道RenderFrame阶段是哪个View在耗时。下拉控制中心的时候抓取trace如下图所示:
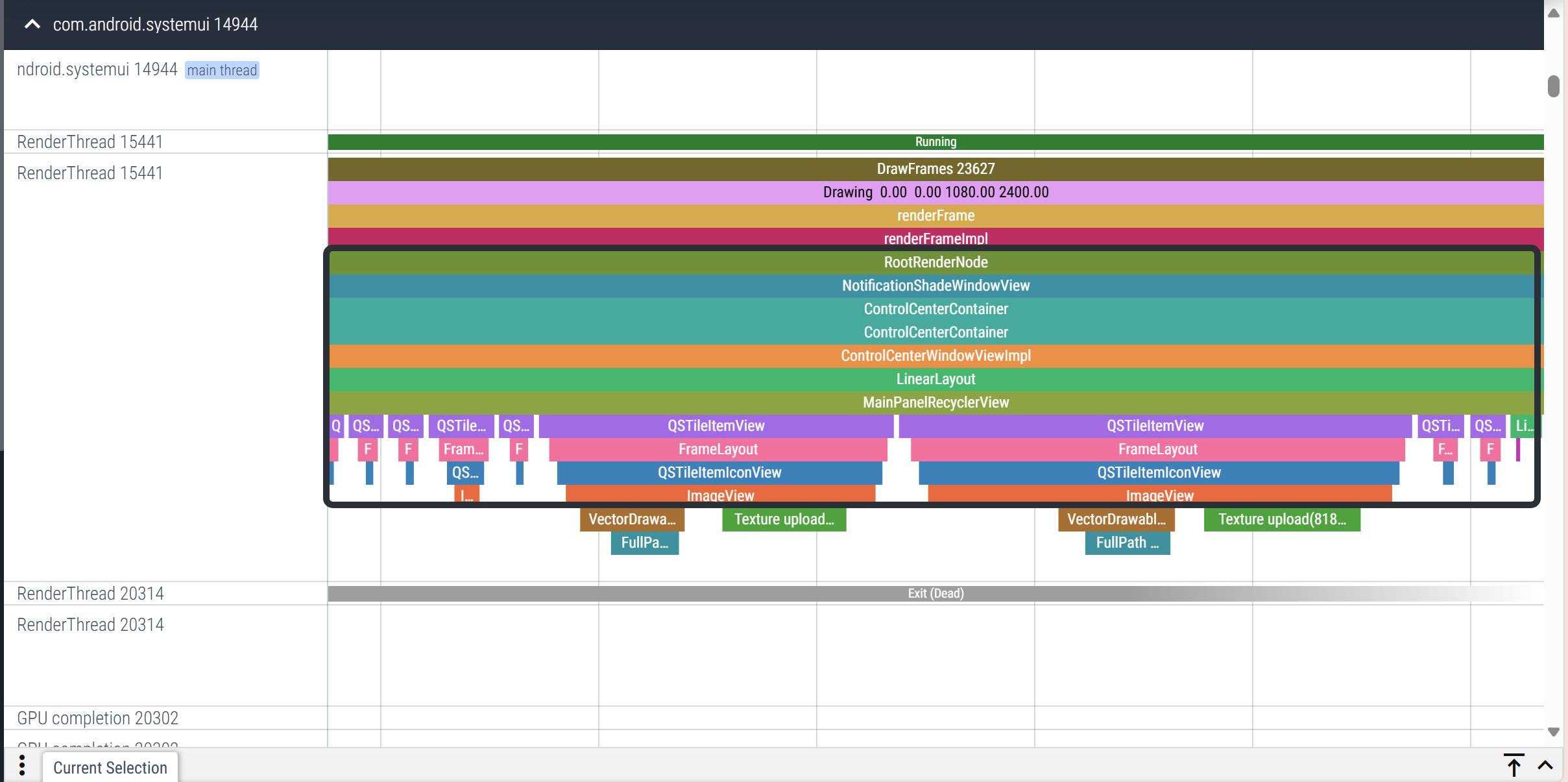
图中黑色框出来的部分是我们刚刚添加的trace,这里可以清晰的看到整个RenderNode树(对应View树)的结构。这样我们可以看到这里的Texture upload操作来自于哪个View,从而定位RenderFrame阶段耗时原因。
flush commands阶段
flush commands阶段主要是在执行RenderTask,其中最常见的OpsTask是RenderTask的一个子类,也就是说OpsTask是一种RenderTask。在OpsTask中又主要是在执行多个GrOp,一般常见的GrOp有FillRectOp,AtlasTextOp,TextureOp等。接下来分别介绍如何定位每个RenderTask和每个GrOp是来自于哪个View。
GrRenderTask
一般来说flush commands阶段就一个OpsTask:

有时候也可能有多个OpsTask,在RenderFrame的flush layers阶段也会有OpsTask:

还有一些不是OpsTask的RenderTask,默认是没有trace的。
这些RenderTask非常耗时,但是通过默认的trace信息我们无法得知这些OpsTask是来自于哪个View,因此这里需要添加一些额外的trace来定位。
一般RenderTask都是RenderFrame阶段添加的,我们可以在添加的时候打印出其指针值,然后在后续执行的时候也打印出指针值,这样我们就知道每个RenderTask是从哪个View添加的了。
首先在RenderTask执行的时候打印其指针值:(external/skia/src/gpu/ganesh/GrRenderTask.h)
class GrRenderTask : public SkRefCnt {
...
bool execute(GrOpFlushState* flushState) {
std::stringstream ss;
ss << "GrRenderTask::execute " << this;
std::string s = ss.str();
TRACE_EVENT0_ALWAYS("skia.gpu", TRACE_STR_STATIC(s.c_str()));
return this->onExecute(flushState);
}
...
}这里只演示了在GrRenderTask::execute方法添加trace,同样也需要在GrRenderTask::prePrepare和GrRenderTask::prepare方法添加trace。
然后在添加RenderTask的位置也打印出其指针值:(external/skia/src/gpu/ganesh/GrDrawingManager.cpp)
GrRenderTask* GrDrawingManager::insertTaskBeforeLast(sk_sp<GrRenderTask> task) {
if (!task) {
return nullptr;
}
std::stringstream ss;
ss << "appendTask1 " << task.get();
std::string s = ss.str();
TRACE_EVENT0_ALWAYS("skia.gpu", TRACE_STR_STATIC(s.c_str()));
if (fDAG.empty()) {
return fDAG.push_back(std::move(task)).get();
}
if (!fReorderBlockerTaskIndices.empty() && fReorderBlockerTaskIndices.back() == fDAG.size()) {
fReorderBlockerTaskIndices.back()++;
}
fDAG.push_back(std::move(task));
auto& penultimate = fDAG.fromBack(1);
fDAG.back().swap(penultimate);
return penultimate.get();
}
GrRenderTask* GrDrawingManager::appendTask(sk_sp<GrRenderTask> task) {
if (!task) {
return nullptr;
}
std::stringstream ss;
ss << "appendTask2 " << task.get();
std::string s = ss.str();
TRACE_EVENT0_ALWAYS("skia.gpu", TRACE_STR_STATIC(s.c_str()));
if (task->blocksReordering()) {
fReorderBlockerTaskIndices.push_back(fDAG.size());
}
return fDAG.push_back(std::move(task)).get();
}这里有2个方法添加RenderTask,打印trace时分别用appendTask1和appendTask2区分。这里添加RenderTask的位置无法确定这个RenderTask的类型,所以我们可以在所有调用这2个方法的位置也打印trace,例如:(external/skia/src/gpu/ganesh/GrDrawingManager.cpp)
...
sk_sp<skgpu::ganesh::OpsTask> GrDrawingManager::newOpsTask(GrSurfaceProxyView surfaceView,
sk_sp<GrArenas> arenas) {
TRACE_EVENT0_ALWAYS("skia.gpu", TRACE_FUNC);
SkDEBUGCODE(this->validate());
SkASSERT(fContext);
this->closeActiveOpsTask();
sk_sp<skgpu::ganesh::OpsTask> opsTask(new skgpu::ganesh::OpsTask(
this, std::move(surfaceView), fContext->priv().auditTrail(), std::move(arenas)));
SkASSERT(this->getLastRenderTask(opsTask->target(0)) == opsTask.get());
this->appendTask(opsTask);
fActiveOpsTask = opsTask.get();
SkDEBUGCODE(this->validate());
return opsTask;
}
void GrDrawingManager::addAtlasTask(sk_sp<GrRenderTask> atlasTask,
GrRenderTask* previousAtlasTask) {
TRACE_EVENT0_ALWAYS("skia.gpu", TRACE_FUNC);
SkDEBUGCODE(this->validate());
SkASSERT(fContext);
if (previousAtlasTask) {
previousAtlasTask->makeClosed(fContext);
for (GrRenderTask* previousAtlasUser : previousAtlasTask->dependents()) {
// Make the new atlas depend on everybody who used the old atlas, and close their tasks.
// This guarantees that the previous atlas is totally out of service before we render
// the next one, meaning there is only ever one atlas active at a time and that they can
// all share the same texture.
atlasTask->addDependency(previousAtlasUser);
previousAtlasUser->makeClosed(fContext);
if (previousAtlasUser == fActiveOpsTask) {
fActiveOpsTask = nullptr;
}
}
}
atlasTask->setFlag(GrRenderTask::kAtlas_Flag);
this->insertTaskBeforeLast(std::move(atlasTask));
SkDEBUGCODE(this->validate());
}
GrTextureResolveRenderTask* GrDrawingManager::newTextureResolveRenderTaskBefore(
const GrCaps& caps) {
TRACE_EVENT0_ALWAYS("skia.gpu", TRACE_FUNC);
// Unlike in the "new opsTask" case, we do not want to close the active opsTask, nor (if we are
// in sorting and opsTask reduction mode) the render tasks that depend on any proxy's current
// state. This is because those opsTasks can still receive new ops and because if they refer to
// the mipmapped version of 'proxy', they will then come to depend on the render task being
// created here.
//
// Add the new textureResolveTask before the fActiveOpsTask (if not in
// sorting/opsTask-splitting-reduction mode) because it will depend upon this resolve task.
// NOTE: Putting it here will also reduce the amount of work required by the topological sort.
GrRenderTask* task = this->insertTaskBeforeLast(sk_make_sp<GrTextureResolveRenderTask>());
return static_cast<GrTextureResolveRenderTask*>(task);
}
...添加完这些trace后抓取一份下拉通知栏的trace:
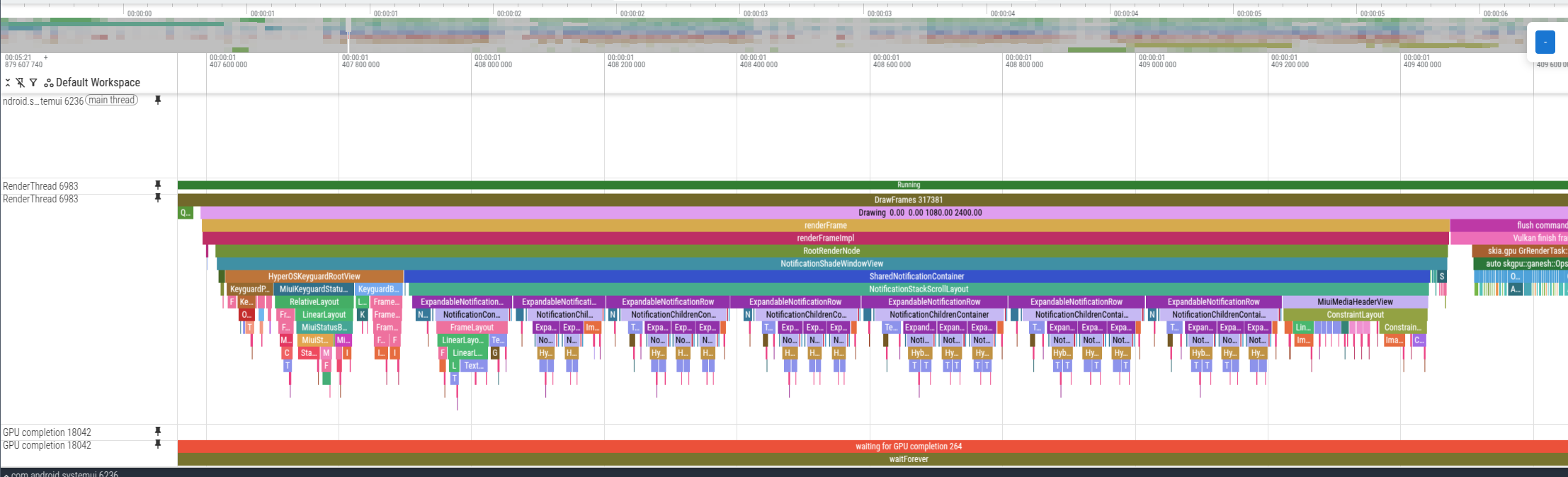
这里可以看到systemui的RT线程特别耗时:
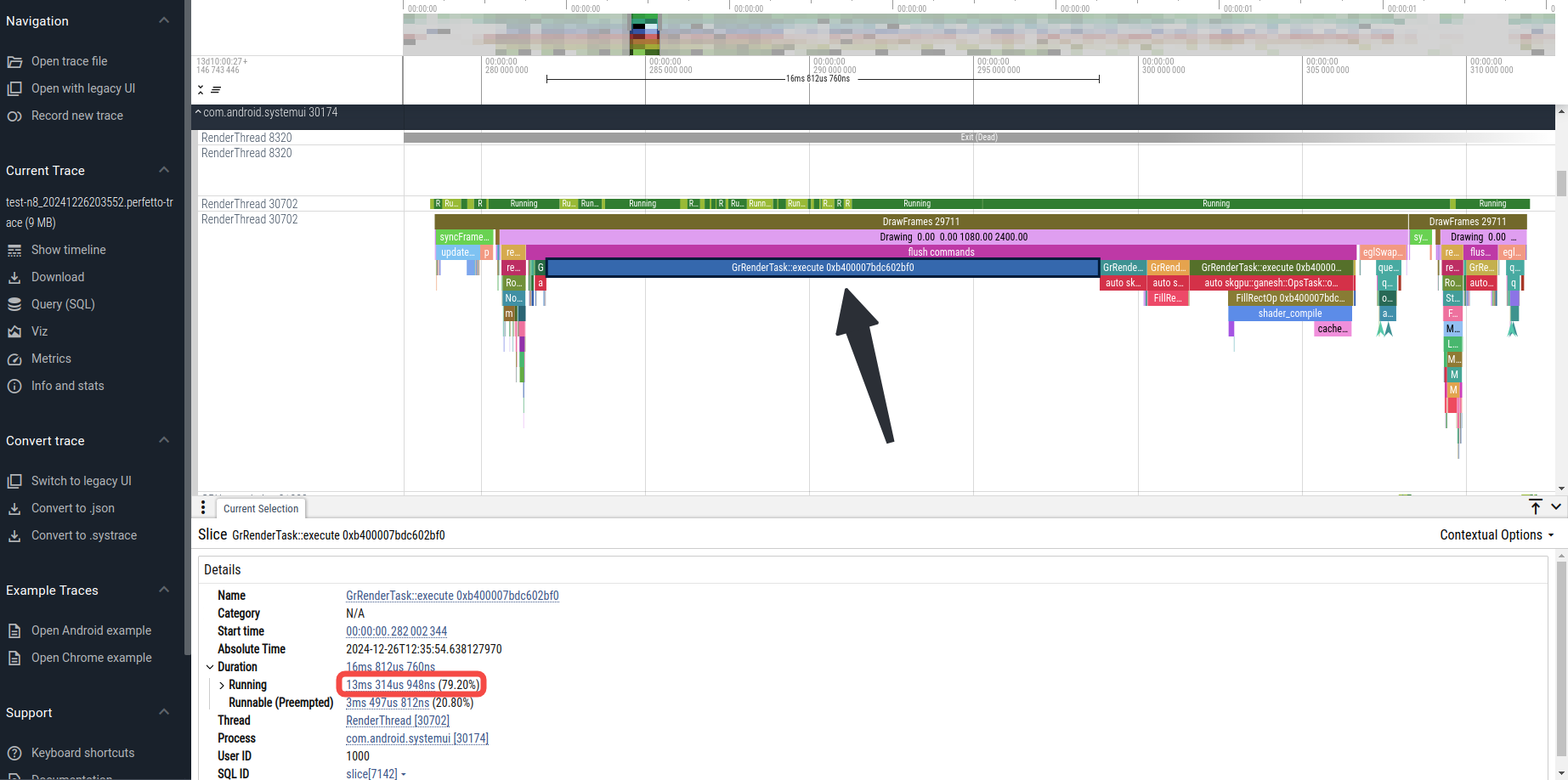
如上图,其中有一个RenderTask的running时长就有13ms。我们已经打印出了这个RenderTask的指针值,接下来在trace中搜索这个指针值:
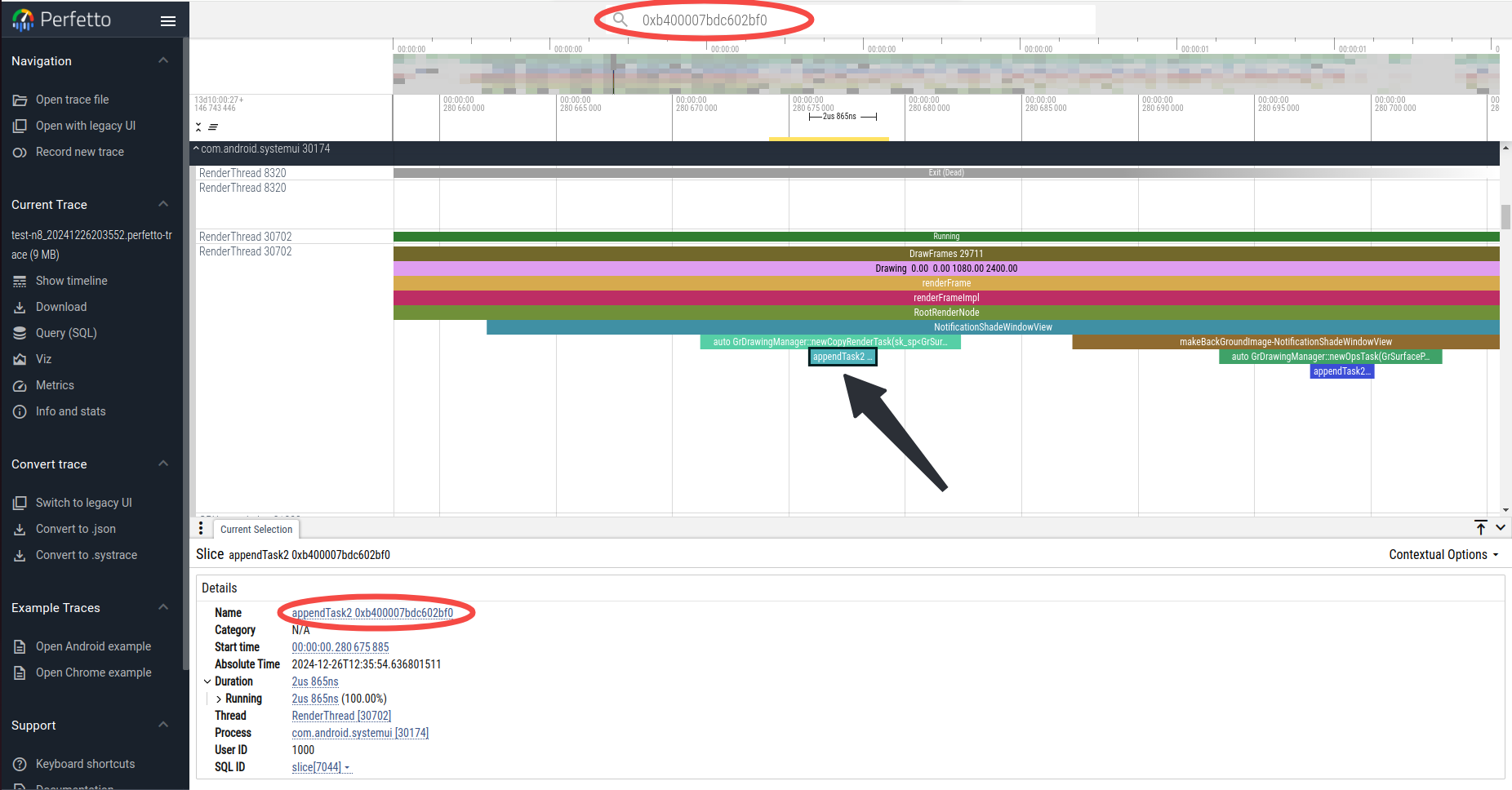
就可以找到在RenderFrame阶段这个RenderTask添加的位置。从上图可以看到,这个RenderTask的类型是CopyRenderTask,是从NotificationShadeWindowView添加上去的。后续再去查这个View用了什么渲染特效就能基本定位耗时来源了。RenderTask的类型非常多,大家有兴趣可以去看skia的源码。
这样添加trace后,我们就可以定位到每个RenderTask来自于具体的哪个View。
GrOp
OpsTask耗时主要是在执行绘制Op操作,将这里放大看如下图所示:

这个图里有FillRectOp,AtlasTextOp,TextureOp。Op类型非常多,大家有兴趣可以去看skia的源码。目前默认的log完全无法定位哪个Op来自于哪个View,有的Op耗时了我们也不知道是哪个View导致的。因此这里需要增加一些信息以供定位。
Op是在RenderFrame阶段添加上去的,因此我们只要在RenderFrame阶段添加Op的时候也把Op打印出来就知道哪个View添加了哪些Op了。但是一般有很多名字一样的Op,因此我们需要同时也把Op的指针也打印出来,这样就可以精确定位flush commands阶段的每个Op是哪个View添加的了。
我们首先在renderFrame阶段添加Op的SurfaceDrawContext::addDrawOp方法中添加trace:(external/skia/src/gpu/ganesh/SurfaceDrawContext.cpp)
void SurfaceDrawContext::addDrawOp(const GrClip* clip,
GrOp::Owner op,
const std::function<WillAddOpFn>& willAddFn) {
ASSERT_SINGLE_OWNER
if (fContext->abandoned()) {
return;
}
GrDrawOp* drawOp = (GrDrawOp*)op.get();
SkDEBUGCODE(this->validate();)
SkDEBUGCODE(drawOp->fAddDrawOpCalled = true;)
GR_CREATE_TRACE_MARKER_CONTEXT("SurfaceDrawContext", "addDrawOp", fContext);
std::stringstream ss;
ss << drawOp->name() << " " << drawOp;
std::string s = ss.str();
TRACE_EVENT0_ALWAYS("skia.gpu", TRACE_STR_STATIC(s.c_str())); // 打印Op的名字和指针
...
}然后再去flush commands阶段打印Op的位置添加打印Op的指针:(external/skia/src/gpu/ganesh/ops/GrOp.h)
class GrOp : private SkNoncopyable {
...
/** Issues the op's commands to GrGpu. */
void execute(GrOpFlushState* state, const SkRect& chainBounds) {
std::stringstream ss;
ss << name() << " " << this;
std::string s = ss.str();
TRACE_EVENT0_ALWAYS("skia.gpu", TRACE_STR_STATIC(s.c_str())); // 打印Op的名字和指针
this->onExecute(state, chainBounds);
}
...
}这里展示了在GrOp::execute方法中添加trace的代码,也需要在GrOp::prepare方法和GrOp::prePrepare方法中做同样的修改。
完成这些trace的添加后,就可以定位每个Op来自于哪个View了。还是看之前的trace,其实已经带了这些Op的修改。例如这里的RT线程大约第5帧绘制超时:
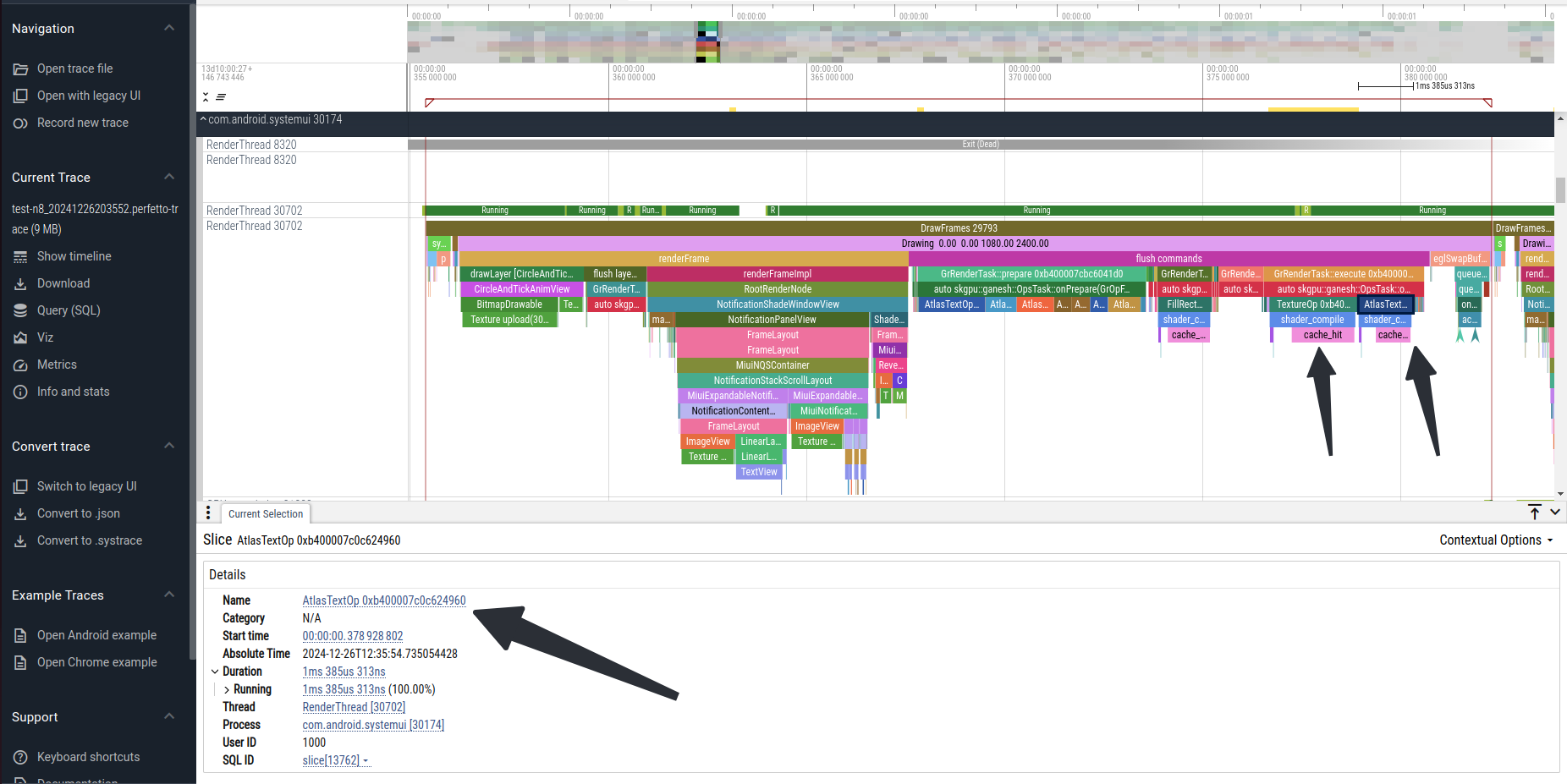
最后一个OpsTask中有2个Op,分别是TextureOp和AtlasTextOp,running时长都超过了1ms。我们搜索他们的指针值,就可以在RenderFrame阶段找到添加这些Op的位置:
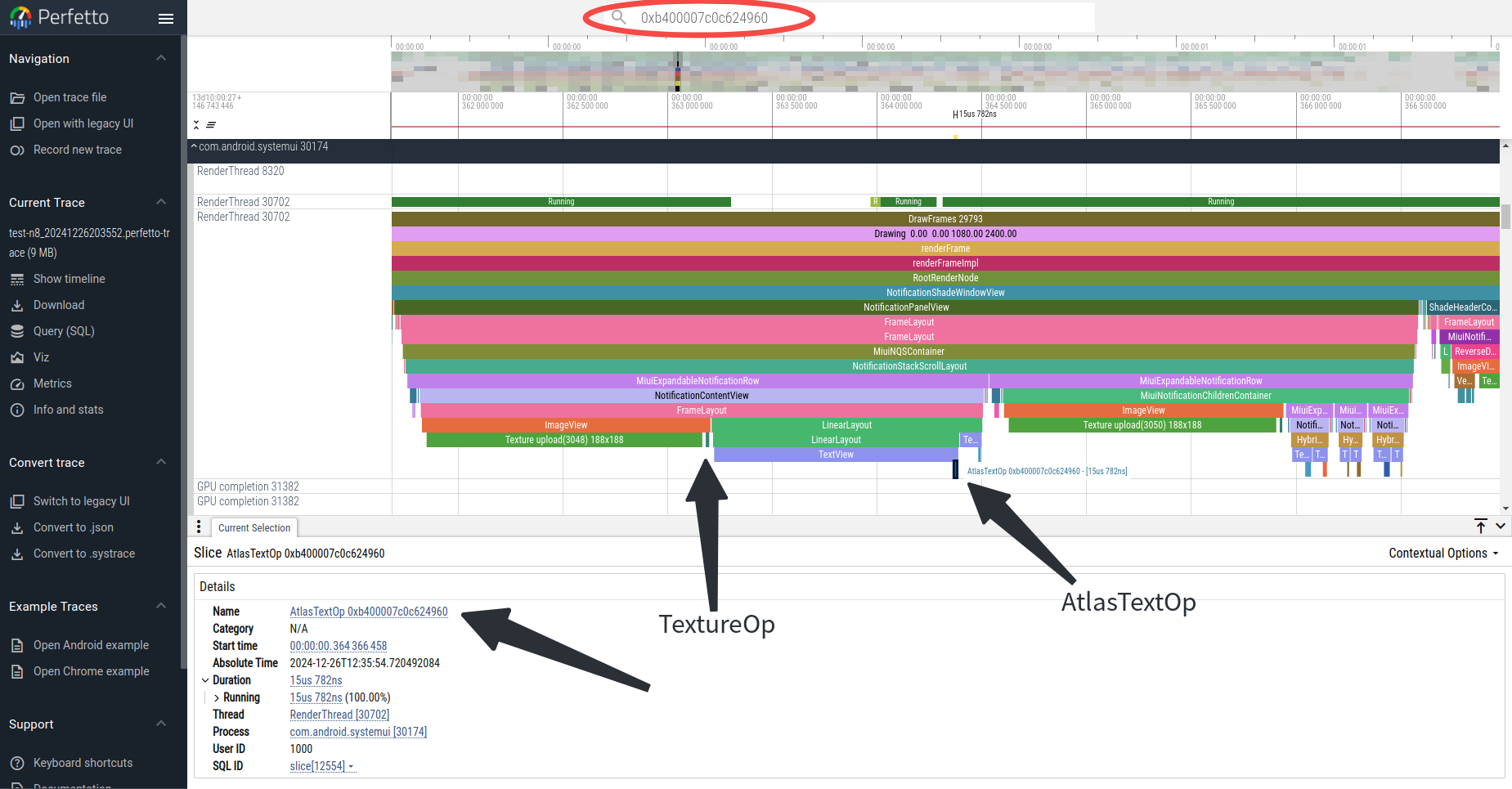
从上图可以看到,TextureOp和AtlasTextOp分别是NotificationContentView下面的ImageView和TextView添加的。
这样添加trace后,我们就可以定位到每个Op是来自于具体的哪个View。
总结
使用了本文的方式,可以拆解出RT线程中RenderFrame阶段和flush commands阶段的每段耗具体来自于哪个View,也就是说我们可以看出如果我们屏蔽了某个View,我们可以预估出RT线程的耗时会减少多少。
本文完整的****debug change:
https://gerrit.pt.mioffice.cn/c/platform/frameworks/base/+/4890635
https://gerrit.pt.mioffice.cn/c/platform/external/skia/+/4890669
2025年4月11号更新:
本文添加trace的change已合入master-v-qcom和master-25q2分支:
https://gerrit.pt.mioffice.cn/c/platform/frameworks/base/+/5266153
https://gerrit.pt.mioffice.cn/c/platform/external/skia/+/5266136
后续可以直接使用以下命令动态打开这些trace:
adb shell setprop persist.sys.sf.dynamic.cachemiss.trace true
adb shell "stop; start"