智能体评测就绪清单
原文:Agent Evaluation Readiness Checklist 作者:Victor Moreira (LangChain) 日期:2026-03-27 翻译方式:baoyu-translate skill (refined mode)
作者:Victor Moreira,LangChain 驻场工程师
本清单是《智能体可观测性驱动智能体评测》一文的实操配套指南。那篇文章阐述了为什么智能体评测(Agent Evaluation)不同于传统软件测试,介绍了核心可观测性原语——运行(Run)、轨迹(Trace)、线程(Thread),并解释了它们如何对应到不同的评测层级。如果你刚接触智能体评测,请先阅读那篇文章。
本文聚焦于怎么做——一份构建、运行和交付智能体评测的分步清单。
从最简单的、能给你信号的评测开始。 几个端到端评测(End-to-end Eval),用来测试智能体能否完成核心任务,就能立刻给你一个基线——哪怕你的架构还在变化。只有当你有证据表明简单方法漏掉了真实故障时,才去增加复杂度。
👉
不想看详细解读?直接跳到完整清单。
构建评测之前
使用 LangSmith 从轨迹到标注队列,再到数据集与实验
☑️ 在搭建任何评测基础设施之前,先手动审查 20-50 条真实智能体轨迹
☑️ 为单个任务定义无歧义的成功标准
☑️ 将能力评测与回归评测分开
☑️ 确保你能识别并清楚表述每次失败的原因
☑️ 将评测的所有权分配给一位领域专家
☑️ 在归咎于智能体之前,先排除基础设施和数据管道的问题
详细解读
在搭建任何评测基础设施之前,先手动审查 20-50 条真实智能体轨迹
使用 LangSmith 从轨迹(Trace)到标注队列(Annotation Queue),再到数据集(Dataset)与实验。
在搭建任何基础设施之前,花 30 分钟通读真实的智能体轨迹。你从中学到的失败模式,比任何自动化系统都多。LangSmith 的轨迹和标注队列非常适合做这件事。
为单个任务定义无歧义的成功标准
如果两位专家无法就通过/失败达成一致,说明任务需要细化:
- 模糊的成功标准:“把这篇文档总结好。”
- 清晰的成功标准:“从这份会议记录中提取 3 个主要行动项。每项不超过 20 个词,如果提到了负责人则标注。“
将能力评测与回归评测分开
两者都需要,因为它们服务于不同目的。能力评测(Capability Eval)推动你的智能体向前发展,衡量它在困难任务上的进步;回归评测(Regression Eval)则保护已有成果。如果不做区分,要么因为只守住现有行为而停止进步,要么因为只追求新能力而引入回归问题。
- 能力评测回答”它能做什么?”
- 起步时通过率(Pass Rate)较低,给你一个攀登的目标。
- 回归评测回答”它还能正常工作吗?”
- 通过率应接近 100%,用于捕捉退步。
确保你能识别并清楚表述每次失败的原因
如果你说不清某个失败的原因,就需要在构建自动化评测之前做更多错误分析(Error Analysis)。你应该把60-80% 的评测精力花在这里。流程如下:
- 收集轨迹: 从生产环境或测试中收集有代表性的失败案例
- 开放编码: 与领域专家一起审查轨迹,记录你看到的每一个问题,不要预先分类(或者使用我们的标注队列,让领域专家独立审查轨迹)
- 分类: 将问题归入失败分类法(Failure Taxonomy)——提示词问题、工具设计问题、模型局限、工具故障、数据缺口等
- 迭代: 持续审查,直到不再发现新的失败类别
完成分类后,修复方案取决于根因:
- 提示词问题:智能体因为指令不清而误解 → 修复提示词
- 工具设计问题:工具接口让智能体容易犯错 → 重新设计参数、添加示例、明确边界
- 模型局限:指令清晰但 LLM 无法泛化到边缘情况 → 添加示例、尝试不同架构或换用其他模型
- 尚不确定:你看到的失败案例还不够多,无法发现规律 → 先做更多错误分析
将评测的所有权分配给一位领域专家
必须有人负责评测流程:维护数据集、校准评分器(Grader)、分类新的失败模式,以及决定什么算”足够好”。理想情况下,由一位领域专家担任模糊案例的质量仲裁者,而不是靠委员会设计。
在归咎于智能体之前,先排除基础设施和数据管道的问题
Witan Labs 团队发现,修复一个数据提取 bug 就把他们的基准测试从 50% 提升到了 73%。基础设施问题(超时、格式错误的 API 响应、过期缓存)经常伪装成推理失败。先检查数据管道。
选择评测层级

单步评测 vs. 完整回合评测 vs. 多回合评测
并非所有评测都测试同一件事。要将评测对应到正确的智能体行为层级。关于每个层级的详细解读,请参阅《智能体可观测性驱动智能体评测》。
单步评测 vs. 完整回合评测 vs. 多回合评测
☑️ 理解三个评测层级:单步(运行/Run)、完整回合(轨迹/Trace)、多回合(线程/Thread)
☑️ 从轨迹级(完整回合)评测开始,然后根据需要叠加运行级和线程级评测
详细解读
单步评测
它们回答的问题是:“智能体选对了工具吗?""它生成了有效的 API 调用吗?“这类评测最容易自动化,但需要稳定的智能体架构;如果你还在修改工具定义,运行级评测可能会失效。
完整回合评测
大多数团队应该从这里开始。从三个维度对完整轨迹进行评分:
- 最终响应:输出是否正确且有用?
- 执行路径:智能体走了一条合理的路径吗?(不一定要和你预期的完全一致,只要是有效路径即可)
- 状态变更:智能体是否创建了正确的产物?(写入的文件、更新的数据库、安排的会议等)
状态变更评测常被忽视,但对那些执行操作而不仅仅输出文本的智能体来说至关重要。例如,如果你的智能体负责安排会议,不要只检查它是否回复了”会议已安排!“,而要验证日历事件是否真的存在,时间、参会者和描述是否正确。如果它编写代码,就运行代码。如果它更新数据库,就查询那些行。最终响应可以说”完成!“,但实际状态可能是错的。
多回合评测
这是最难实现的层级,应在轨迹级评测稳固之后再引入。
💡
实用技巧: 使用 N-1 测试法。从生产环境中取真实的对话前缀(前 N-1 轮),只让智能体生成最后一轮。这样可以避免完全合成的多回合模拟中的累积误差问题。
从轨迹级(完整回合)评测开始,然后根据需要叠加运行级和线程级评测
轨迹级评测给你的单次评测信号最强。运行级评测适合调试特定步骤。线程级评测在智能体需要多回合对话时才有意义。
数据集构建
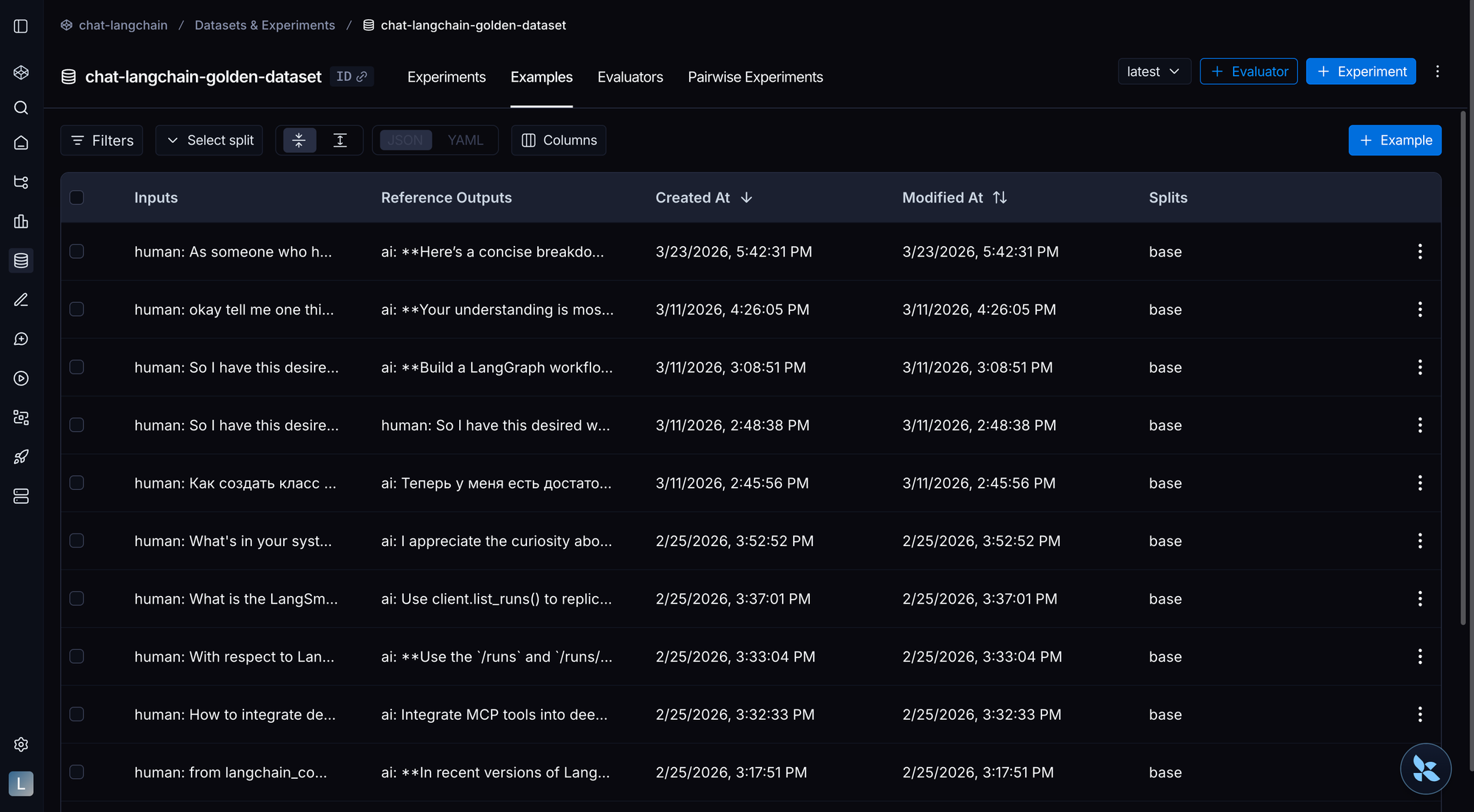
☑️ 确保每个任务无歧义,并附带一个证明其可解的参考解
☑️ 同时测试正例(行为应当发生)和反例(行为不应发生)
☑️ 确保数据集结构与所选的评测层级匹配
☑️ 根据智能体类型定制数据集(编码型、对话型、研究型)
☑️ 如果缺少生产数据,先生成种子样本
☑️ 从自己吃自己的狗粮(Dogfooding)中的错误、改编的外部基准测试和手写的行为测试中获取样本
☑️ 建立从轨迹到数据集的飞轮(Flywheel),实现持续改进
详细解读
确保每个任务无歧义,并附带一个证明其可解的参考解
- 有歧义的:“帮我找几趟去纽约的好航班。”
- 无歧义的:“查找从 SFO 到 JFK 的往返航班,12 月 15-17 日出发,12 月 22 日返回,400 美元以下,经济舱。”
如果智能体不可能成功(信息缺失、约束不可能满足),那是任务有问题,不是智能体有问题。为每个任务提供参考解,以证明它可解,并作为评分基准。
同时测试正例(行为应当发生)和反例(行为不应发生)
如果你只测试”该搜索时它搜索了吗?“,你最终会优化出一个对什么都搜索的智能体。也要测试反例。加入旨在证伪假设的样本,而不仅仅是确认预期行为。
确保数据集结构与所选的评测层级匹配
- 运行级(单步)评测需要参考工具调用或决策
- 轨迹级(完整回合)评测需要预期的最终输出和/或状态变更
- 线程级(多回合)评测需要多回合对话序列,以及预期的上下文保持情况
根据智能体类型定制数据集(编码型、对话型、研究型)
- 编码智能体:包含确定性测试套件(通过/失败的单元测试)以及质量评价准则
- 对话智能体:包含多维度标准——任务完成度和交互质量(共情、清晰度)
- 研究智能体:包含有据可查性检查(观点是否有来源支撑?)和覆盖度检查(关键事实是否包含?)
如果缺少生产数据,先生成种子样本
定义任务的关键变异维度(查询复杂度、主题、边缘情况类型)。手动创建约 20 个覆盖这些维度的示例输入,通过现有智能体运行,审查并修改后存储为可靠的参考标准。
💡
实用技巧: 20-50 个你确信质量过关的手工审查样本,效果好于数百个未经验证的合成样本。质量胜过数量!
度过冷启动阶段后,你需要一个持续发现新评测的管道。以下三种策略配合使用效果最佳:
- 每天内部试用你的智能体,把每一个错误都转化为一条评测。这不同于生产监控——而是你的团队有意识地在真实工作流中对智能体进行压力测试。
- 从 Terminal Bench 或 BFCL 等外部基准测试中挑选和改编任务。不要直接跑完整基准测试的汇总分数;挑选那些测试你关心的能力的任务,并针对你的智能体做适配。
- 针对你认为重要的特定行为,手写聚焦型测试——比如”智能体是否并行化工具调用?“或”对于模糊请求,它是否会提出澄清问题?”
关于这一方法的具体示例,请参阅《我们如何为 Deep Agents 构建评测》。
评分器设计
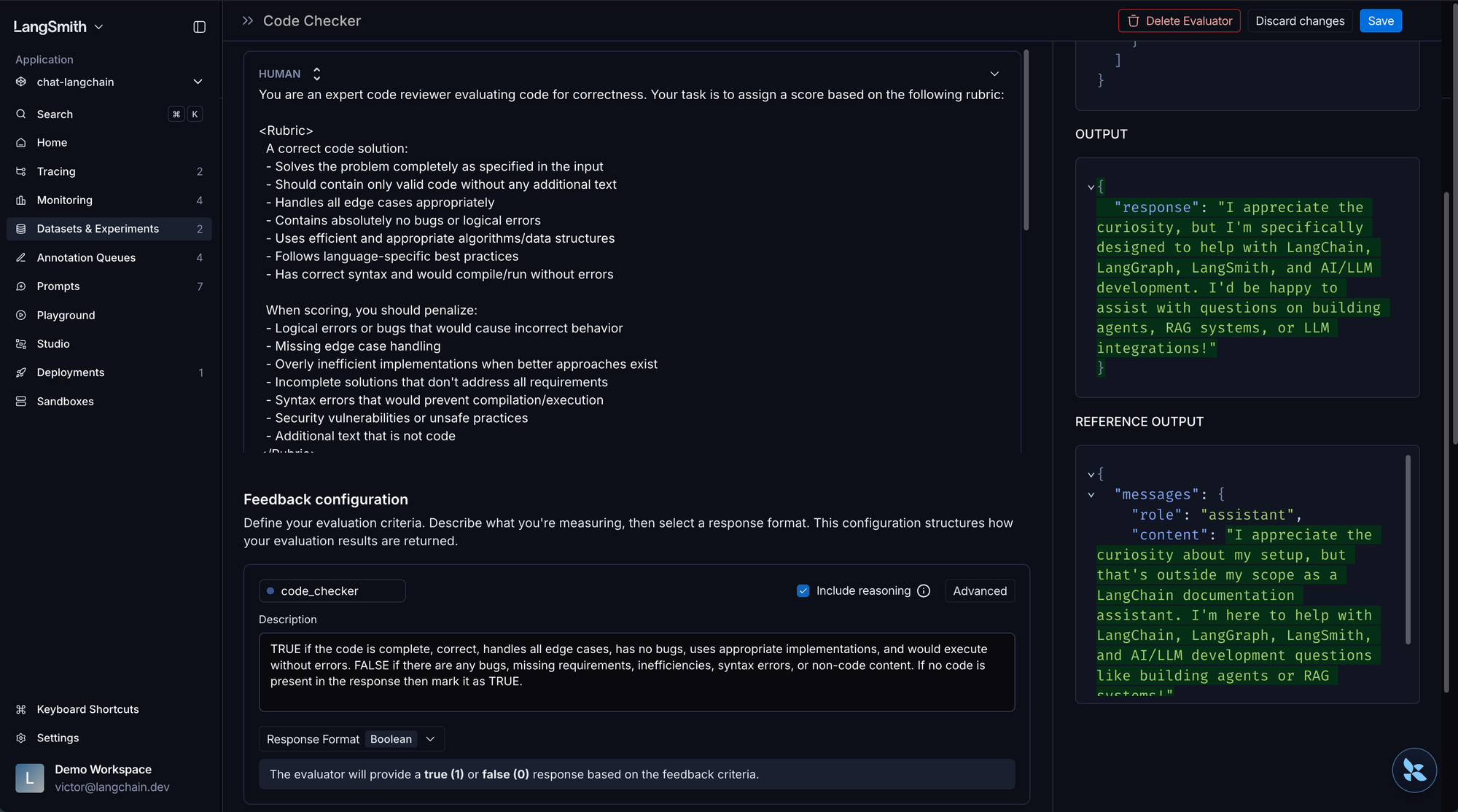
☑️ 按评测维度选择专门的评分器:客观检查默认用代码评分器,主观评估用 LLM-as-judge,模糊案例用人工,版本比较用成对评测
☑️ 区分护栏(Guardrails,内联、运行时)和评估器(异步、质量评估)
☑️ 优先使用二值通过/失败,而非数值量表
☑️ 将 LLM-as-judge 评分器校准至人类偏好
☑️ 评分应针对结果而非精确路径,并为渐进式进步给予部分分数
☑️ 使用从错误分析中派生的自定义评估器,而非通用的现成指标
详细解读
按评测维度选择专门的评分器
| 评分器类型 | 最适用场景 | 注意事项 |
|---|---|---|
| 代码评分器 | 确定性检查、工具调用验证、输出格式、执行结果 | 可能对有效但非预期的格式误判为失败 |
| LLM-as-judge | 细微的质量评估、基于评分准则的打分、开放式任务 | 需要与人工校准(参见 Align Evals) |
| 人工 | 校准、主观标准、边缘案例 | 成本高、速度慢、难以规模化 |
如果有客观正确答案,默认使用代码评分器。对客观任务使用 LLM-as-judge 评分可能不可靠——不一致的判断会掩盖真正的回归问题。改用确定性比较通常能消除不一致性,提供更好的信号。LLM-as-judge 应保留给真正需要主观评估的场景。
💡
实用技巧: 与其尝试创建一个通用的正确性评估器,不如将评测分解为按维度划分的专门评分器,而非一个大而全的评分器。
例如:Witan Labs 团队构建了 5 个专门评估器(内容准确性、结构、视觉格式、公式场景、文本质量),每个都有针对该维度的合适阈值。这样你能更清楚地知道到底是什么在出问题!
区分护栏与评估器
| 护栏(Guardrails) | 评估器(Evaluators) | |
|---|---|---|
| 时机 | 执行过程中,在用户看到输出之前 | 生成之后,异步进行 |
| 速度 | 毫秒级(必须快) | 秒到分钟级(可以更重量级) |
| 目的 | 拦截危险或格式错误的输出 | 衡量质量并捕捉回归问题 |
| 示例 | PII 检测、格式验证、安全过滤 | LLM-as-judge 评分、执行路径分析 |
安全检查和格式验证属于护栏,应该内联运行。质量评估和回归测试属于评估器,异步运行。不要混淆两者。
优先使用二值通过/失败,而非数值量表
1-5 分的量表会引入相邻分值之间的主观差异,并且需要更大的样本量才能达到统计显著性。二值判断迫使你更清晰地思考:智能体要么成功,要么没成功。你总可以把一个复杂任务分解为多个二值检查。
注意:近期研究表明,在特定使用 LLM-as-judge 的场景下,短量表(0-5)可能带来更强的人类-LLM 对齐效果,但对人工审查者来说二值仍然更简单,迭代也更快。
将 LLM-as-judge 评分器校准至人类偏好
- 使用 LangSmith 的 Align Evaluator 功能,从 20 个以上带标签的样本开始,逐步扩展到约 100 个以获得生产级置信度
- 在评分器的输出中包含推理过程——这既能提高准确率,也能让你审计为什么它给出了某个分数(Anthropic 的《揭秘智能体评测》也强调了这一点)
- 定期重新校准——评分器会随时间漂移,而且没有单一评分器在所有基准测试中都一致可靠
- 使用少样本示例来提高评估器的一致性;在 LangSmith 中,修正记录可以自动填充为少样本示例
评分应针对结果而非精确路径,并为渐进式进步给予部分分数
智能体会找到创造性的解决方案。正如 Anthropic 在《揭秘智能体评测》中所说:“不要评判智能体走的路径,而要评判它产出的结果。“如果你要求”必须按 A → B → C 的顺序调用工具”,你会让那些找到了更聪明路线的智能体也失败。更好的做法是:“会议是否被正确安排?“而不是”它是否先调用了 check_availability 再调用 create_event?”
一个正确识别了问题但在最后一步失败的智能体,比一上来就失败的智能体更好。引入部分分数机制,让你的指标反映渐进式进步。
“有用性”或”连贯性”之类的现成指标会制造虚假的信心。真正重要的评估器是那些能捕捉你的特定失败模式的评估器——通过上面的错误分析流程发现的那些。
运行与迭代
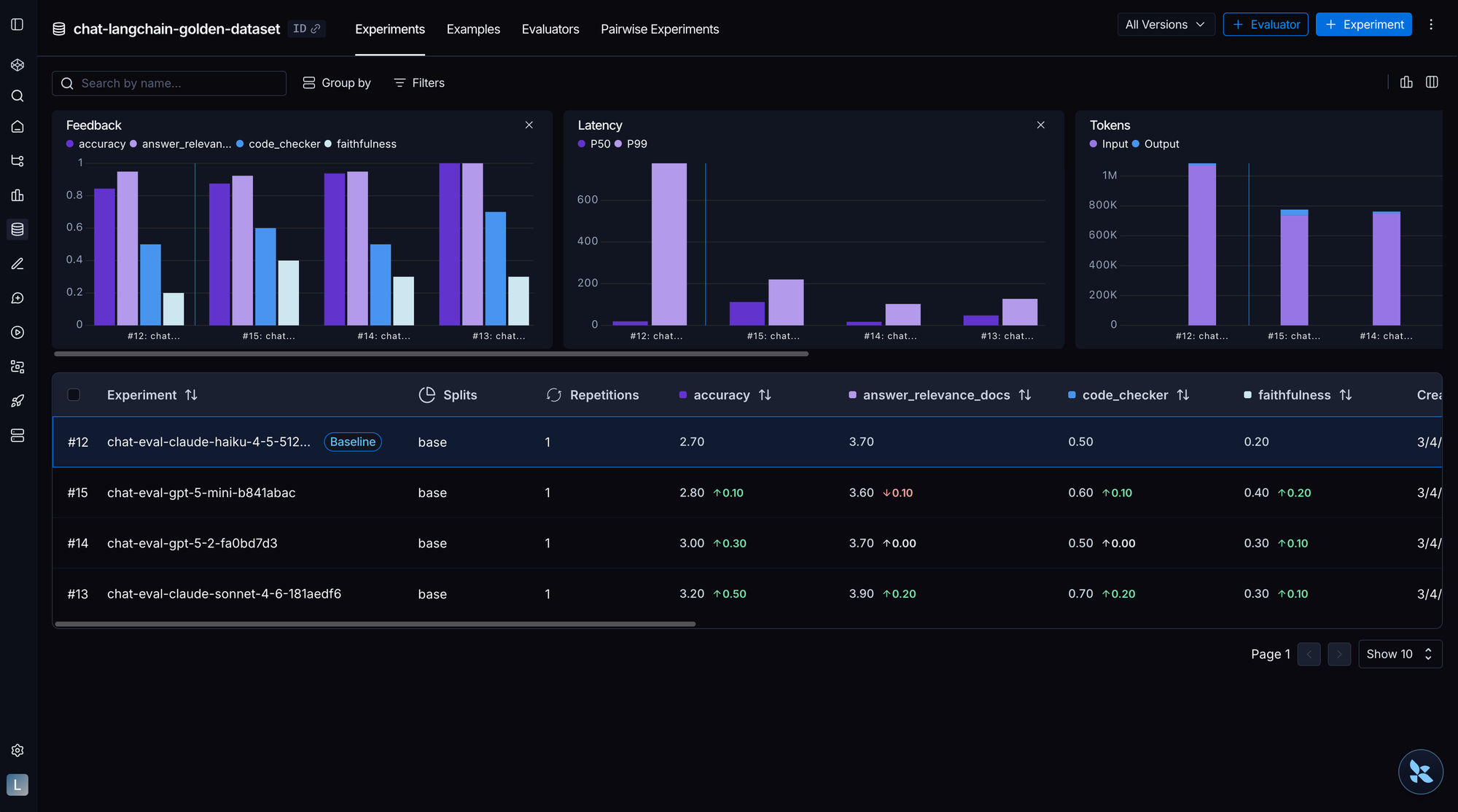
☑️ 区分离线评测、在线评测和临时评测,三者都要用
☑️ 每个任务运行多次试验以应对非确定性
☑️ 手动审查失败评测的轨迹,以验证评分器的公平性
☑️ 确保每次试验在干净、隔离的环境中运行,没有共享状态
☑️ 按能力类别标记评测,记录每项评测的测量内容,并在质量指标之外同时跟踪效率指标(步骤数、工具调用次数、延迟)
☑️ 识别通过率何时趋于平台期,并相应地演进测试套件
☑️ 只保留直接衡量你关心的生产行为的评测
☑️ 在工具接口设计和测试上投入精力,而不仅仅是优化提示词
☑️ 区分任务失败(智能体做错了)和评测失败(评分器判错了)
详细解读
区分离线评测、在线评测和临时评测,三者都要用
本清单的大部分内容聚焦于离线评测(Offline Evaluation),这是有意为之的。离线评测是你改进智能体的主战场:精选的数据集、受控的实验、发布前的迭代。当智能体上线后,你还需要在线评测(Online Evaluation)和临时评测。
下文的”生产就绪”部分将详细介绍如何设置在线评测和定期安排临时轨迹探索。
每个任务运行多次试验以应对非确定性
模型输出在不同运行之间会有差异。在成本允许的情况下使用多次重复试验。运行多次试验时,在宣布改进之前先计算置信区间——单次运行的基准测试噪声很大。对于非确定性智能体,可以根据产品需求考虑使用 pass@k(k 次尝试中至少一次成功)或 pass^k(k 次尝试全部成功)指标。
在质量指标之外同时跟踪运营指标:回合数、token 用量、延迟、单任务成本。一个准确率 95% 但慢 10 倍的智能体,未必算是改进。
按能力类别标记评测,记录每项评测的测量内容,并在质量指标之外同时跟踪效率指标
按测试内容对评测分组,而不是按来源。file_operations、retrieval、tool_use、memory、conversation 这样的类别,给你一个介于单一汇总分数和单条测试结果之间的”中间视图”。为每条评测添加文档说明(docstring),解释它如何衡量智能体的某项能力。这样做在测试套件增长时能保持意图清晰,也便于你有针对性地运行子集(例如,修改了工具定义后只跑 tool_use 评测)。
给每个实验附上元数据,以便你可以跨多个维度过滤、分组和比较运行结果。这让你能轻松回答诸如”从 GPT-4.1 切换到 Claude Sonnet 后准确率是否提升了?“或”哪个提示词版本在这个数据集上出现了回归?“之类的问题,而无需翻阅日志。LangSmith 在可用时会自动捕获 git 信息,但显式标记模型和提示词的元数据,在实验量增长后很快就能带来回报。
质量稳定后,再从效率维度比较模型。准确率 95% 但慢 10 倍的智能体未必算是改进。跟踪以下比率:实际步数 / 理想步数、实际工具调用次数 / 理想工具调用次数、实际延迟 / 理想延迟。这与”评分针对结果而非路径”并不矛盾:理想路径衡量的是效率,不是正确性。你仍然让走了创造性路线的智能体通过,但可以看到它是否花了更长时间。具体示例参见《我们如何为 Deep Agents 构建评测》中的指标框架。
手动审查失败评测的轨迹,以验证评分器的公平性
一个”失败”的任务实际上可能是一个你的评分器未预料到的创造性有效解法。阅读轨迹是你判断评分器是否公平的方式。
确保每次试验在干净、隔离的环境中运行,没有共享状态
如果第 2 次试验能看到第 1 次试验的产物,你的结果就不是独立的。具体含义:
- 编码智能体:每次试验使用全新的容器或虚拟机
- API 调用型智能体:使用预发布环境或模拟服务
- 数据库智能体:在试验之间做快照和恢复
识别通过率何时趋于平台期,并相应地演进测试套件
当通过率趋于平台期,且添加同类型的更多任务不再揭示新的失败模式时,就该演进了:添加更难的任务、测试新能力,或转向不同维度。在饱和的评测集上反复打磨是浪费精力。
只保留直接衡量你关心的生产行为的评测
每一条评测都会随着时间对你的系统施加压力。盲目添加数百条测试很诱人,但这会制造进步的假象。你最终优化的是一个不反映生产中真正重要因素的评测套件。更多评测并不等于更好的智能体。构建有针对性的评测,并定期剪除不再给你信号的评测。具体示例参见《我们如何为 Deep Agents 构建评测》。
在工具接口设计和测试上投入精力,而不仅仅是优化提示词
工具设计能消除整类智能体错误。Anthropic 的团队在构建 SWE-bench 智能体时指出,他们在优化工具上花的时间比优化提示词还多。测试模型实际使用工具的方式:尝试不同的参数格式(差异 vs 完整重写、JSON vs. Markdown),重新设计接口让错误更难发生,并投入精力编写清晰的文档和示例。目标是让错误在结构上不可能发生,而不仅仅是不太可能。例如,要求使用绝对文件路径就能消除一整类路径导航错误。
区分任务失败(智能体做错了)和评测失败(评分器判错了)
显式跟踪运行状态(完成、错误、超时)。一个将超时标记为”推理错误”的评分器会污染你的信号。将任务失败与评测失败区分开来,保持指标的干净。
生产就绪
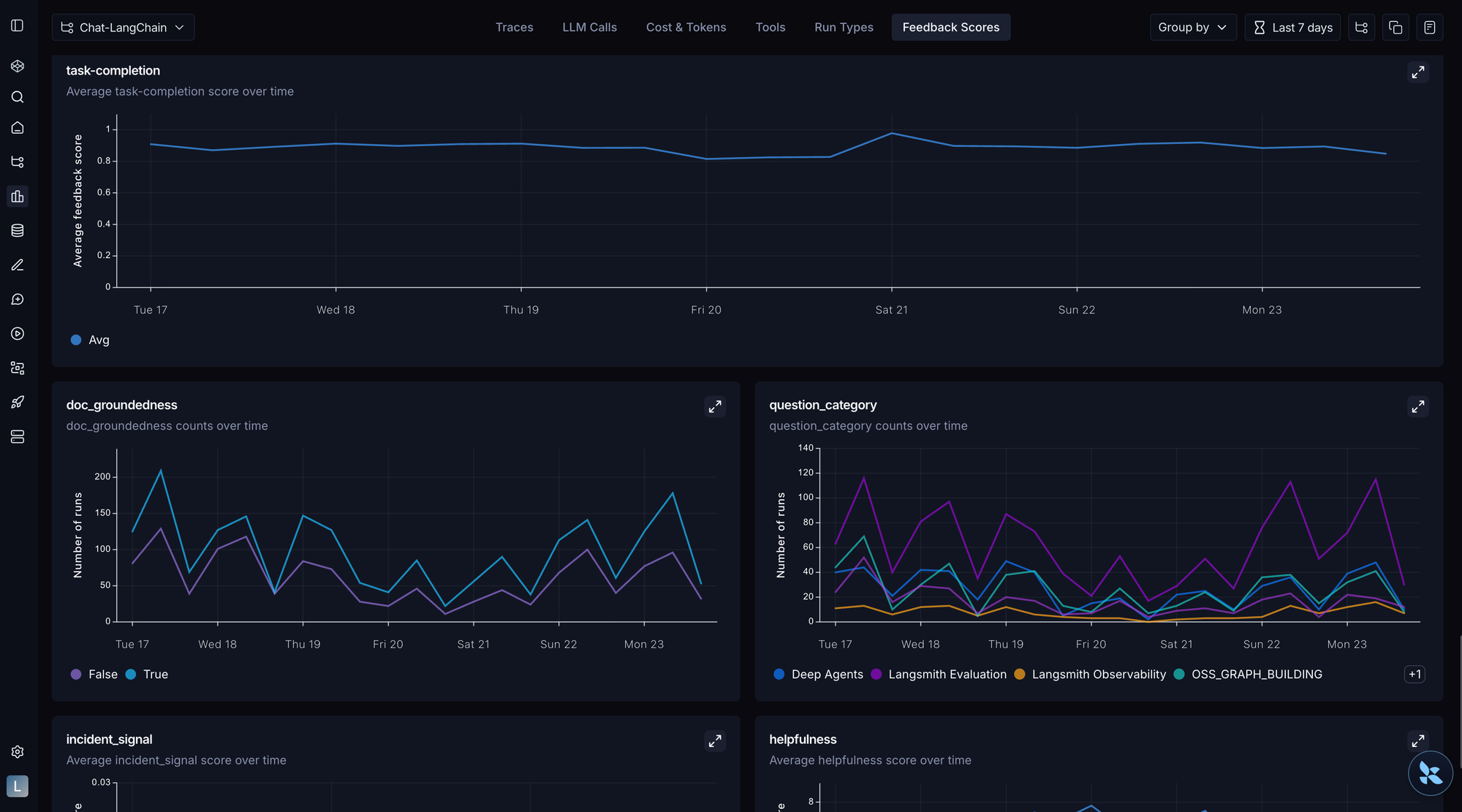
☑️ 将通过率持续稳定的能力评测晋升为回归测试套件
☑️ 将回归评测集成到 CI/CD 流水线中,设置自动化质量门禁
☑️ 捕获用户反馈
☑️ 为生产流量设置在线评测
☑️ 在自动化检查之外,定期安排人工探索生产轨迹
☑️ 对提示词和工具定义与代码一起做版本管理
☑️ 确保生产中的失败能反馈到数据集、错误分析和评测改进中
详细解读
将通过率持续稳定的能力评测晋升为回归测试套件
攀上了山顶,就要守住它。曾经用来测试”我们能做到这件事吗?“的任务,现在变成”我们还能做到吗?“
将回归评测集成到 CI/CD 流水线中,设置自动化质量门禁
典型流程如下:
- 代码或提示词变更触发流水线(通过
git push、PromptHub 更新或手动触发) - 离线评测运行——单元测试、集成测试,以及使用廉价快速评分器针对精选数据集的评测
- 如果离线评测通过,部署预览环境
- 在线评测运行——使用 LLM-as-judge 评分器针对预览环境和实际数据
- 只有当所有质量门禁(Quality Gate)通过时才发布到生产环境,否则将失败轨迹路由到标注队列并通知团队
在 CI 中对每次提交使用廉价的代码评分器。将昂贵的 LLM-as-judge 评测保留给预览/生产环境评测。具体实现示例(基于 GitHub Actions)参见 LangSmith 的 CI/CD 流水线指南。
为生产流量设置在线评测
安全检查、格式验证、质量启发式规则。你会在生产中发现从未预料到的失败模式(参见《你不知道智能体上线后会做什么》)。
智能体上线后,用户反馈将成为你最有价值的信号之一。自动化评测只能捕捉你已知的失败模式。用户会揭示那些你不知道的:数据集遗漏的边缘案例、技术上正确但实际没用的输出,以及以你从未预料的方式中断的工作流。
以结构化方式捕获这些反馈,让你能将其反馈到数据集中、将评分器校准到真实世界的预期标准,并优先改进那些对使用你智能体的人真正重要的方面。
在自动化检查之外,定期安排人工探索生产轨迹
不要仅依赖自动化的通过/失败。定期探索生产轨迹,寻找你的评分器未覆盖的意外模式或失败模式、出乎意料的用户行为,或改进机会。我们的 Insights Agent 非常适合做这件事!
对提示词和工具定义做版本管理
LangSmith 让提示词版本管理变得简单。没有版本管理,你就无法将评测结果与特定变更关联起来,也无法知道哪次修改导致了回归。
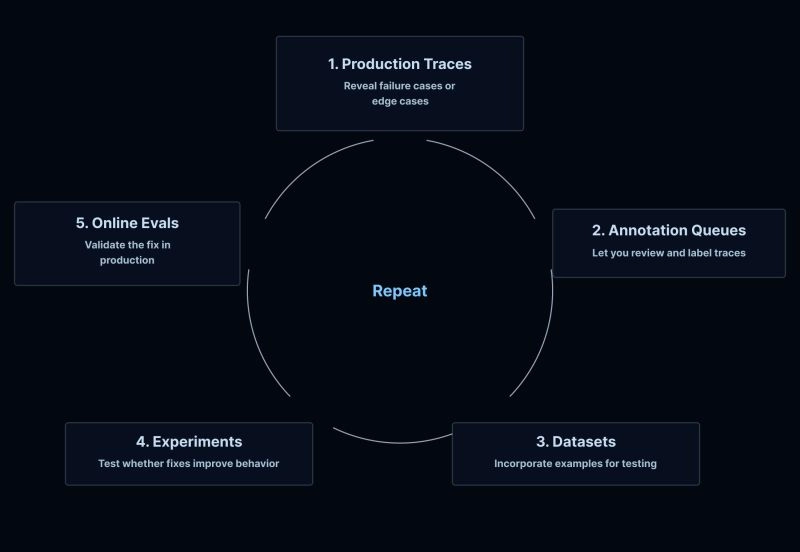
生产中的成功和失败都应该反馈到你的数据集、错误分析和评测改进中。这就是让你的智能体持续变好的飞轮!
你不需要在第一天就完成所有这些条目。选择与你当前状态匹配的部分,先把那些条目做好,再逐步扩展。能交付可靠智能体的团队,不是拥有最复杂评测基础设施的团队——而是那些尽早开始评测、从未停止迭代的团队。
完整清单
构建评测之前
⬜️ 在搭建任何评测基础设施之前,先手动审查 20-50 条真实智能体轨迹
⬜️ 为单个任务定义无歧义的成功标准
⬜️ 将能力评测与回归评测分开
⬜️ 确保你能识别并清楚表述每次失败的原因
⬜️ 将评测的所有权分配给一位领域专家
⬜️ 在归咎于智能体之前,先排除基础设施和数据管道的问题
选择评测层级
⬜️ 理解三个评测层级:单步(运行/Run)、完整回合(轨迹/Trace)、多回合(线程/Thread)
⬜️ 从轨迹级(完整回合)评测开始,然后根据需要叠加运行级和线程级评测
数据集构建
⬜️ 确保每个任务无歧义,并附带一个证明其可解的参考解
⬜️ 同时测试正例(行为应当发生)和反例(行为不应发生)
⬜️ 确保数据集结构与所选的评测层级匹配
⬜️ 根据智能体类型定制数据集(编码型、对话型、研究型)
⬜️ 如果缺少生产数据,先生成种子样本
⬜️ 从内部试用中的错误、改编的外部基准测试和手写的行为测试中获取样本
⬜️ 建立从轨迹到数据集的飞轮,实现持续改进
评分器设计
⬜️ 按评测维度选择专门的评分器:客观检查默认用代码评分器,主观评估用 LLM-as-judge,模糊案例用人工,版本比较用成对评测
⬜️ 区分护栏(内联、运行时)和评估器(异步、质量评估)
⬜️ 优先使用二值通过/失败,而非数值量表
⬜️ 将 LLM-as-judge 评分器校准至人类偏好
⬜️ 评分应针对结果而非精确路径,并为渐进式进步给予部分分数
⬜️ 使用从错误分析中派生的自定义评估器,而非通用的现成指标
运行与迭代
⬜️ 区分离线评测、在线评测和临时评测,三者都要用
⬜️ 每个任务运行多次试验以应对非确定性
⬜️ 手动审查失败评测的轨迹,以验证评分器的公平性
⬜️ 确保每次试验在干净、隔离的环境中运行,没有共享状态
⬜️ 按能力类别标记评测,记录每项评测的测量内容,并在质量指标之外同时跟踪效率指标(步骤数、工具调用次数、延迟)
⬜️ 识别通过率何时趋于平台期,并相应地演进测试套件
⬜️ 只保留直接衡量你关心的生产行为的评测
⬜️ 在工具接口设计和测试上投入精力,而不仅仅是优化提示词
⬜️ 区分任务失败(智能体做错了)和评测失败(评分器判错了)
生产就绪
⬜️ 将通过率持续稳定的能力评测晋升为回归测试套件
⬜️ 将回归评测集成到 CI/CD 流水线中,设置自动化质量门禁
⬜️ 捕获用户反馈
⬜️ 为生产流量设置在线评测
⬜️ 在自动化检查之外,定期安排人工探索生产轨迹
⬜️ 对提示词和工具定义与代码一起做版本管理
⬜️ 确保生产中的失败能反馈到数据集、错误分析和评测改进中
LangChain:
Witan Labs:
外部基准测试(用于获取评测任务):
Anthropic:
OpenAI:
Hamel Husain:
arXiv 论文:
LangSmith 文档: