AI 智能体的持续学习
关于 AI 持续学习(Continual Learning)的讨论,大多聚焦于一件事:更新模型权重。但对于 AI 智能体来说,学习可以发生在三个截然不同的层面:模型(Model)、Harness 和上下文(Context)。理解这三者的差异,会从根本上改变你对”如何构建持续改进系统”的思考方式。
智能体系统(Agentic System)的三个主要层次:
- 模型:模型权重本身。
- Harness:围绕模型的 Harness,驱动智能体的所有实例运行。具体来说,它包括驱动智能体的代码,以及始终内置于 Harness 的指令和工具。
- 上下文:存在于 Harness 之外的附加信息(指令、Skills 等),用于对 Harness 进行配置。
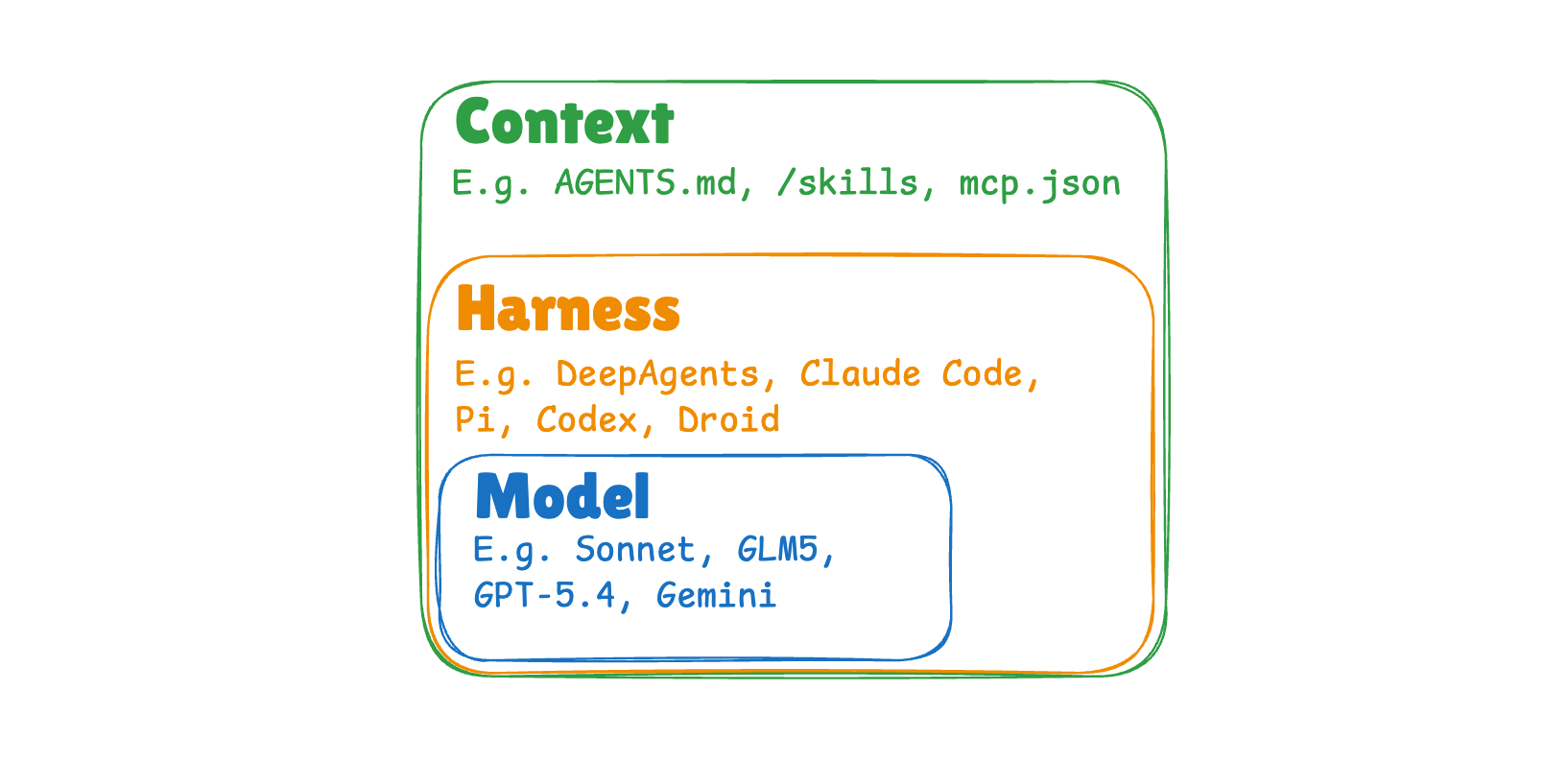
示例 #1:以编码智能体(Coding Agent)Claude Code 为例:
- 模型:claude-sonnet 等
- Harness:Claude Code
- 用户上下文:CLAUDE.md、/skills、mcp.json
示例 #2:以 OpenClaw 为例:
- 模型:多种模型
- Harness:Pi 及其他脚手架
- 智能体上下文:SOUL.md、来自 ClawHub 的 Skills
谈到持续学习,大多数人会直接联想到模型层。但实际上,AI 系统可以在这三个层面中的任何一个进行学习。
模型层的持续学习
大多数人谈论持续学习时,最常指的就是更新模型权重。
相关技术包括 SFT(Supervised Fine-Tuning,监督微调)、RL(Reinforcement Learning,强化学习,如 GRPO)等。
这一层面的核心挑战是灾难性遗忘(Catastrophic Forgetting)——当模型在新数据或新任务上更新后,往往会在先前已掌握的能力上出现退化。这至今仍是开放的研究课题。
当人们为特定智能体系统训练模型时(例如,可以将 OpenAI 的 Codex 模型视为专门为其 Codex 智能体训练的),通常是针对整个智能体系统进行。理论上可以做到更细的粒度——比如为每个用户训练一个 LoRA——但实践中主要还是在智能体层面完成。
Harness 层的持续学习
如前所述,Harness 指的是驱动智能体的代码,以及始终内置于 Harness 的指令和工具。
随着 Harness 的日益普及,已有多篇论文探讨如何优化 Harness。
其中一篇近期的工作是 Meta-Harness: End-to-End Optimization of Model Harnesses。
其核心思路是让智能体在循环中运行。首先在一批任务上运行智能体并进行评估,然后将所有运行日志存入文件系统,再让一个编码智能体分析这些 Traces,提出对 Harness 代码的改进建议。
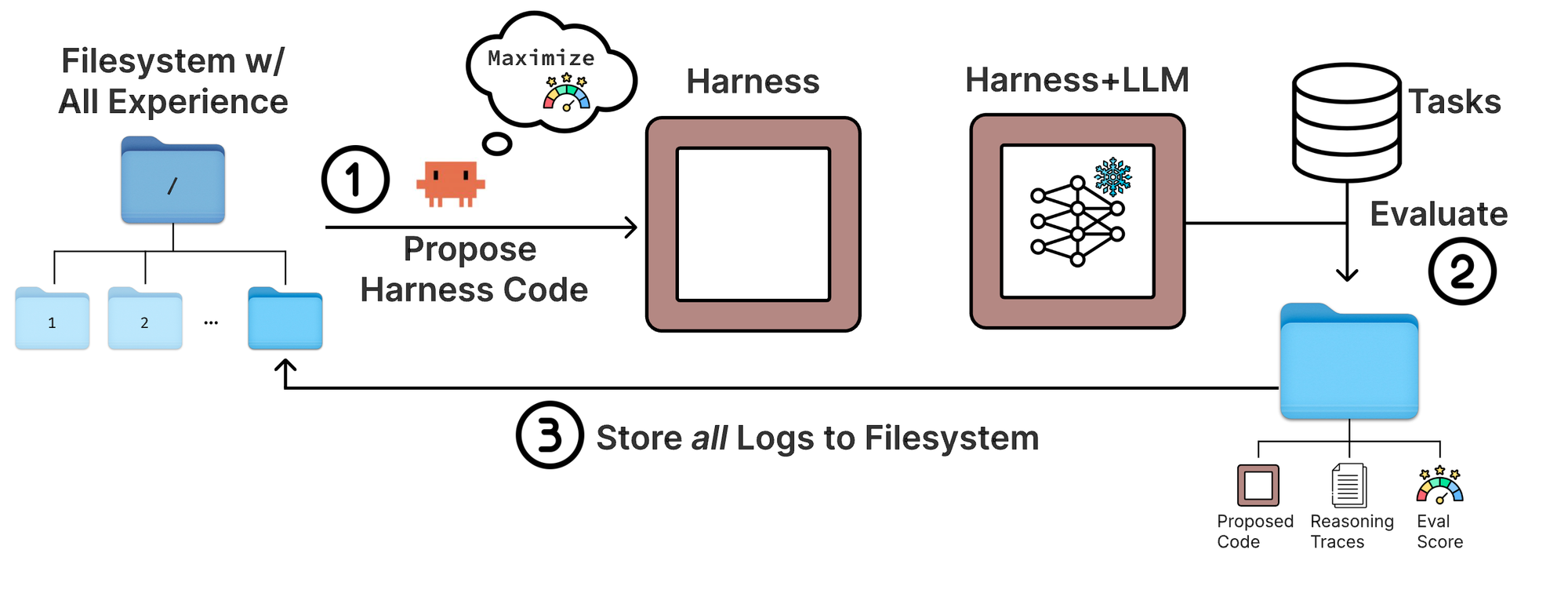
与模型层的持续学习类似,Harness 层的学习通常也在智能体层面进行。理论上可以做到更细的粒度(例如为每个用户学习不同的 Harness 代码),但目前实践中尚不多见。
上下文层的持续学习
“上下文”存在于 Harness 之外,用于对 Harness 进行配置。上下文包括指令、Skills,甚至工具。这也常被称为记忆(Memory)。
同类型的上下文也存在于 Harness 内部(例如,Harness 可能包含基础系统提示词和 Skills)。关键区别在于:它是 Harness 的组成部分,还是外部配置。
上下文学习可以在多个级别进行。
在智能体级别——智能体拥有持久化的”记忆”,并随时间更新自身配置。一个典型的例子是 OpenClaw,它拥有自己的 SOUL.md,会随着使用不断更新。
更常见的做法是在租户级别(用户、组织、团队等)进行上下文学习。每个租户拥有各自的上下文,并随时间持续更新。相关产品包括 Hex 的 Context Studio、Decagon 的 Duet 和 Sierra 的 Explorer。
你也可以混合搭配!比如一个智能体可以同时具备智能体级别、用户级别和组织级别的上下文更新。这些更新可以通过两种方式进行:
- 事后离线处理。与 Harness 更新类似——对近期的 Traces 进行批量分析,提取洞察并更新上下文。OpenClaw 将这一过程称为”做梦”(Dreaming)。
- 在热路径上实时更新。智能体在执行核心任务的过程中,可以自行决定(或由用户提示)更新自身记忆。
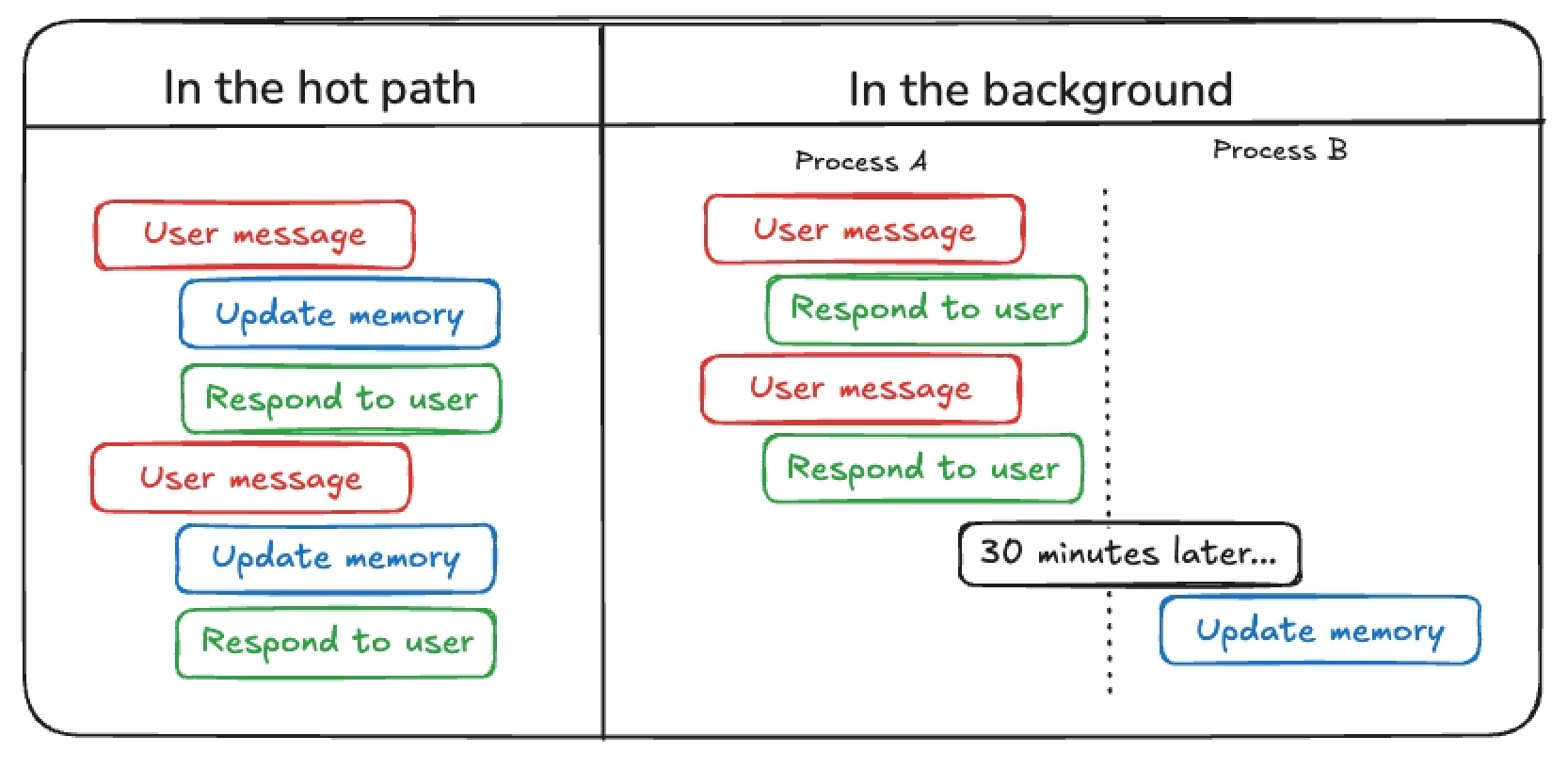
另一个值得考虑的维度是记忆更新的显式程度:是由用户主动提示智能体记住某些内容,还是智能体根据 Harness 中的核心指令自动进行记忆?
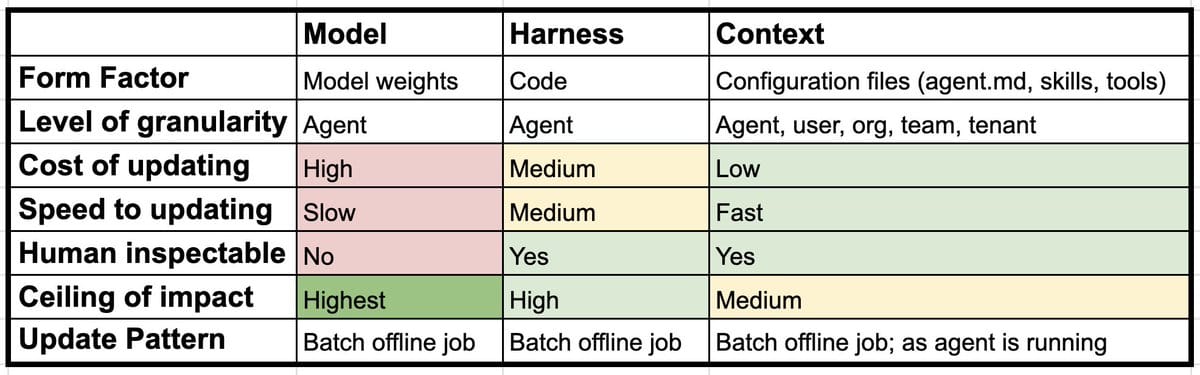
对比
Traces 是核心
上述所有流程都依赖于 Traces(执行轨迹)——即智能体完整的执行路径记录。LangSmith 是我们的平台,核心功能之一就是帮助收集 Traces。
收集到的 Traces 可以用于多种用途。
如果想更新模型,可以收集 Traces,然后与 Prime Intellect 等公司合作训练自有模型。
如果想改进 Harness,可以使用 LangSmith CLI 和 LangSmith Skills,让编码智能体访问这些 Traces。我们正是用这种方式改进了 Deep Agents(我们的开源、模型无关的通用基础 Harness)在 Terminal Bench 上的表现。
如果想随时间学习上下文(无论是智能体级别、用户级别还是组织级别),那么你的智能体 Harness 需要支持这一能力。Deep Agents——我们首选的 Harness——提供了生产就绪的支持。请参阅相关文档,了解如何实现用户级别记忆、后台学习等功能。