ShareSkills AI 工程化探索
来源: 飞书文档 注: 文档中的图片因权限限制无法自动下载,保留原始飞书链接;白板已转换为文字流程描述。
背景
Claude Code 辅助工作,碰到痛点就和 AI 一起封装成 Skills(AI 的专项能力包)。碰到问题就解决,解决完发现可以复用就留下来,深入到每个地方再进行汇总。
这篇讲的是:几个重要 skill 为什么存在、碰了什么墙、最后怎么设计的、怎么保证持续变好。按我实际探索的顺序讲。
全景
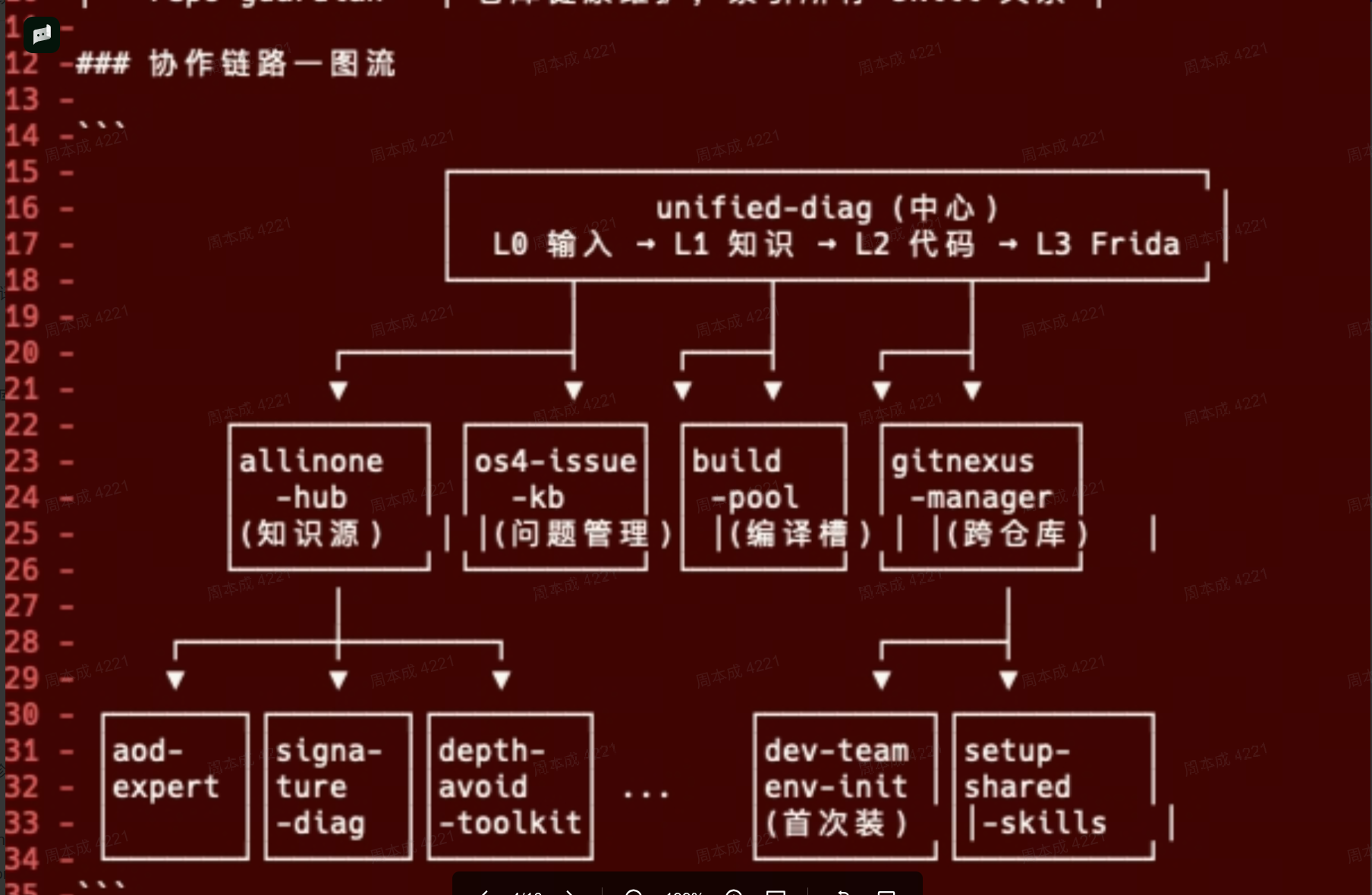
白板: 全景架构图
┌─── 使用者只接触这里 ──────────────────────────────────────────┐ │ /learn沉淀 /diag诊断 /build编译 /commit提交 /review审查 │ │ BB-8自动化 │ └──────────────────────────────────────────────────────────────────┘ ↓ ↓ ↓ ↓ ↓ ┌─── 引擎层 ───────────────────────────────────────────────────────┐ │ unified-diag ──→ 时钟/AOD │ 编辑器 │ 十字楼 │ 编译部署 │ 代码审查 │ 问题管理 │ │ ↕ 专项 Skills │ │ contrib/多人贡献 ──→ 知识库 ←── self-evolve │ └──────────────────────────────────────────────────────────────────┘
| 指标 | 数值 |
|---|---|
| Skills | 135 |
| Commands | 18 |
| Git 提交 | 316 |
| 贡献者 | 15 人 |
| 知识领域 | 锁屏/AOD/编辑器/十字楼/签名/景深/个性化/无障碍 |
| 自动化 Agent | BB-8(远端 7x24) |
第一步:解决自己的重复劳动
aar-deploy — 编译部署自动化
痛点:
- 每次部署 SystemUI 要改多个引用文件(aar 文件 + 版本号 + mapping + 配置),非常繁琐
- SystemUI 仓库 owner 多,提 change 审批流程重
- 锁屏连调一天跑十几次这个流程
设计: 「改代码 → 编译 AAR → 部署 SystemUI → 提 change」从 5 分钟压到 1 句话。
build-pool — 打包目录池
痛点:
- 同时开 20-30 个终端窗口,7-8 个并行分析不同问题
- 同一目录互相踩
- review 等很久,等待期间代码被其他任务改乱
- AI 分析问题时也需要编译验证
白板: build-pool 流程图
任务A:bug-1 → slot comm-1 ←·互不干扰·→ slot comm-2 ← 任务B:bug-2 ↑ AI验证 ────────────────→ slot comm-3 ──┘
设计理念: 不冲突,快速开新的。锁机制是君子协定级别,够用。人和 AI 共用同一套池。
clouddev-systemui-build — 云端编译
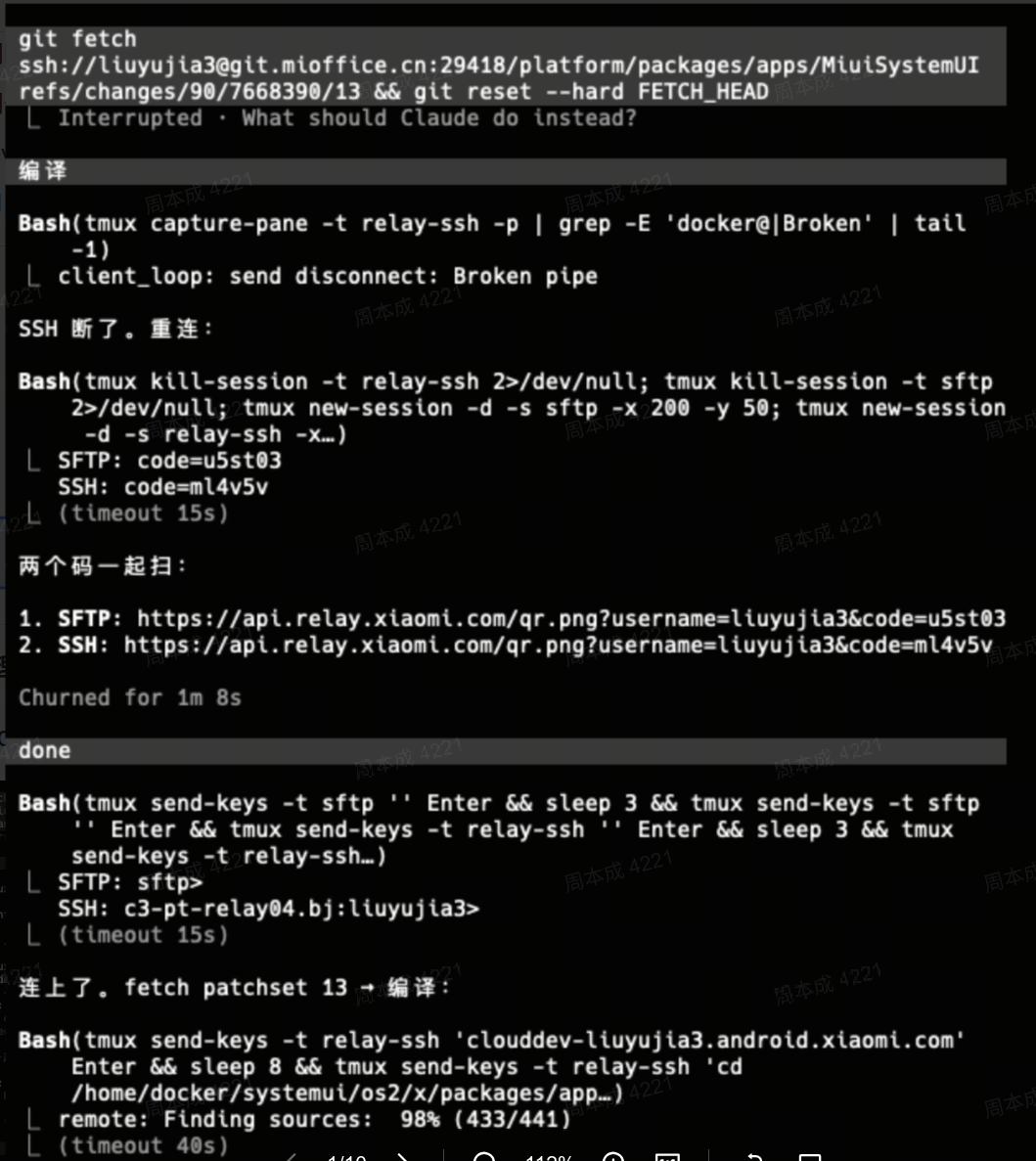
痛点: 手动上传文件到云端、拉代码很慢、bbm 查版本、流程长易忘。
一个问题催生三个 skill:clouddev-systemui-build + relay-sftp + clouddev-mount。
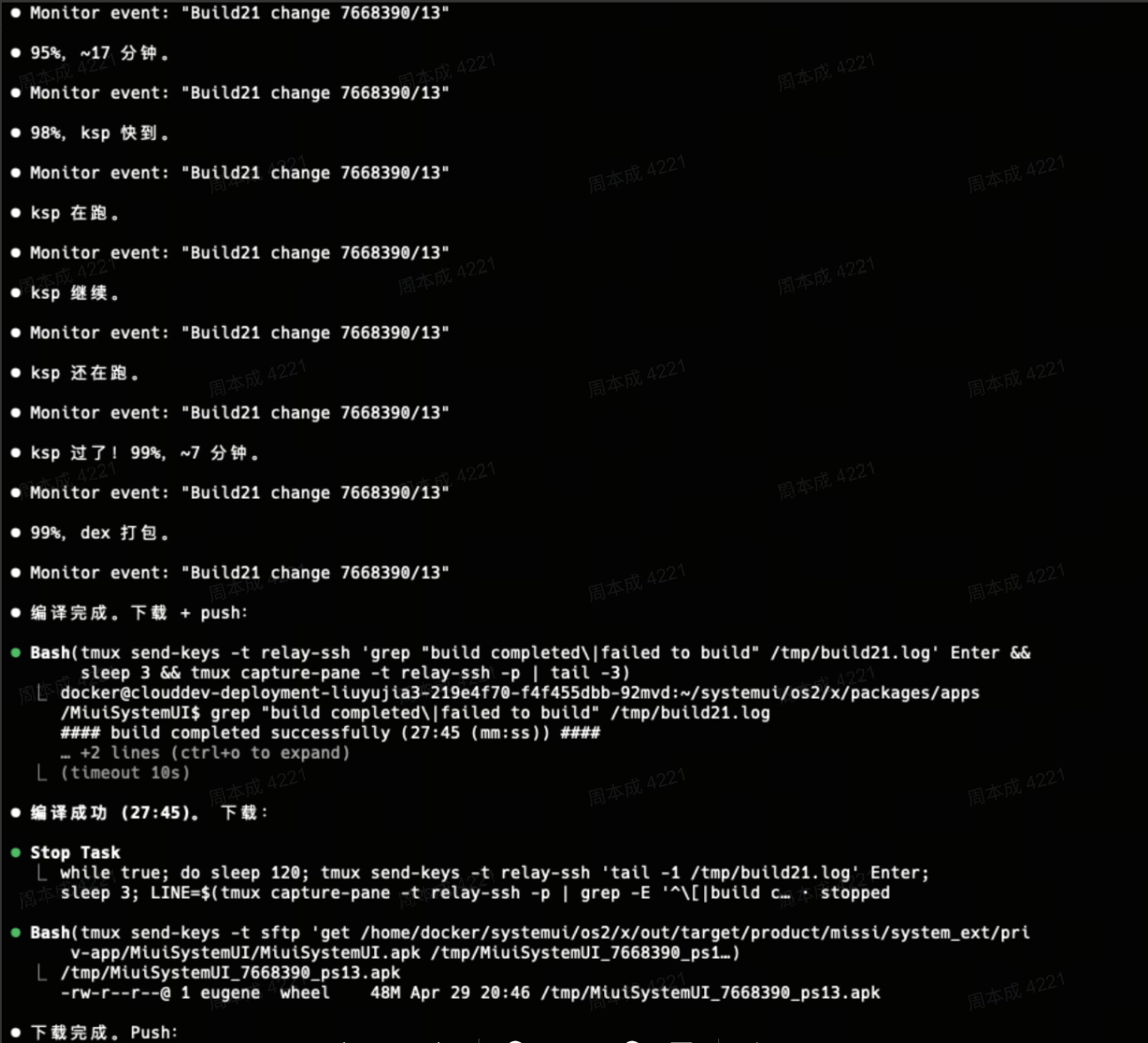
corgi-build — ROM 打包
一个下午 18 步对话,从零到完整 skill。
方法论:渐进式知识注入——先跑通再补全,用纠偏代替规划。详见 构建过程。
第二步:分析经验想留下来
allinone-hub — 从零散 skill 到知识库
过程:
- 每次分析完一个 AllInOne 时钟问题,顺手封装成一个小 skill(颜色/占位符/签名/AOD联动…)
- 积累了十几个零散的领域 skill
- 发现它们有共性:都是查案例、查代码路径、查日志 tag
- 汇总成 allinone-hub——把所有零散知识收到一个地方统一查
不是一开始就想做知识库,是做了很多小 skill 后发现需要一个汇总的地方。 这个模式后来重复了一次:领域知识库多了 → 倒逼出 unified-diag 统一入口。
/learn — 知识沉淀入口
核心理念:每次分析都是一次知识的沉淀,不该浪费。
1 句话触发,AI 自己分类和格式化。不只存 bug 经验——架构知识、方法论、代码路径都能 learn。多人隔离:用户名目录 + 时间戳文件名,零冲突。
/learn 的完整展开在「第八步」详细讲——它和 self-evolve、eval 配合是整套体系最关键的部分。
第三步:领域 skill 多了需要统一入口
unified-diag — 统一诊断引擎
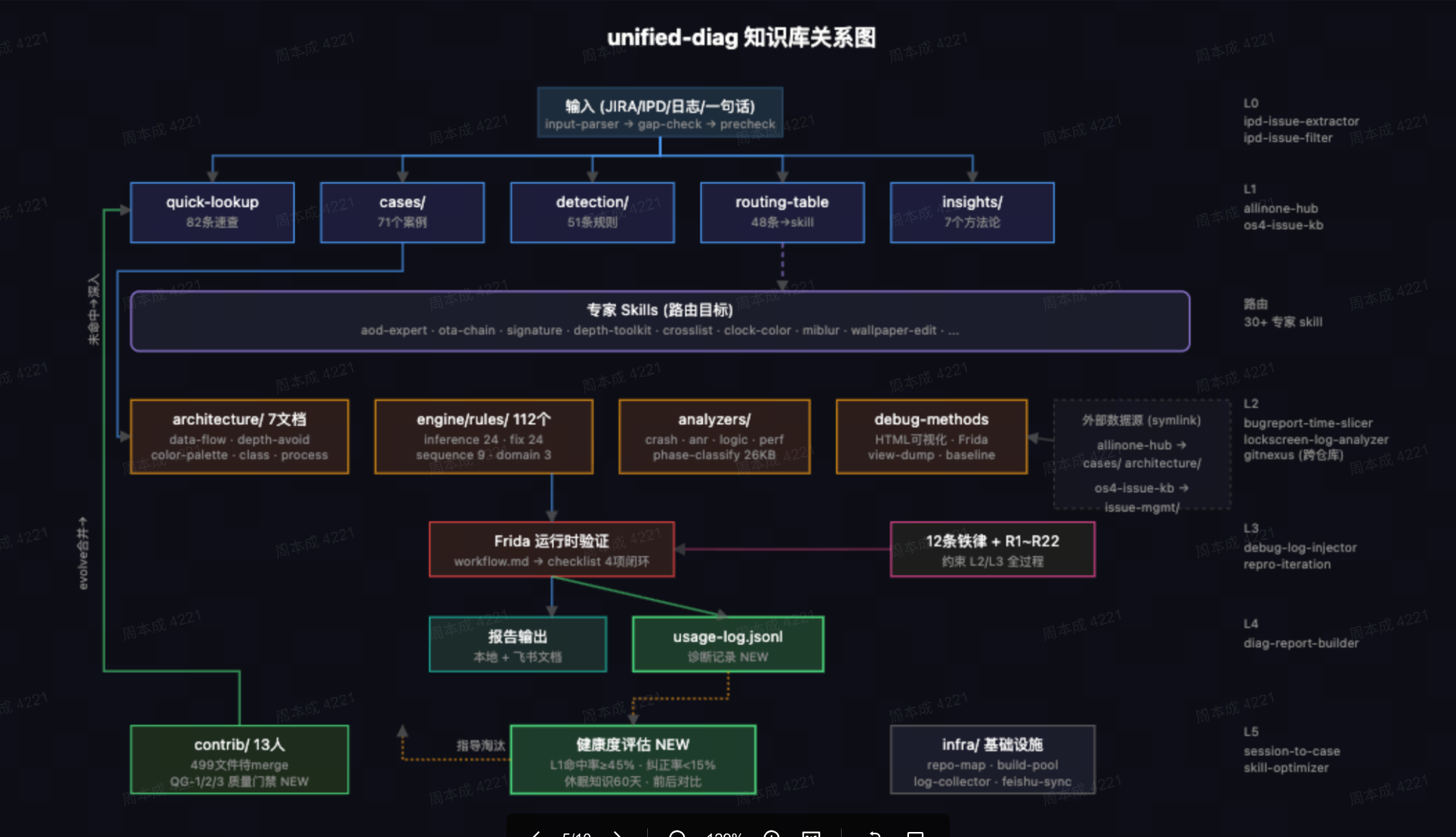
诞生逻辑:
- 先有了 allinone-hub,后来编辑器、十字楼、签名各领域也有了知识
- 用户得记住碰到什么问题该调哪个 → 不现实
- 需要一个统一入口自动路由
白板: unified-diag 路由流程
用户描述问题 ↓ ◇ 知识路由 ◇ ↙ ↓ ↘ ↘ 时钟 编辑器 十字楼 未匹配 ↓ ↓ ↓ ↓ allinone editor crosslist 推理引擎 -hub skills skills ↓ 假设→验证→报告 ↓ /learn ↓ (反馈回知识路由)
从散装到汇总: 不是先设计架构再填内容,是内容倒逼出架构。
第四步:同事要用 → 怎么共享
setup-shared-skills — 仓库管理
碰了三次墙:
- 灵感来自 cc-switch 软链机制(研究 micode 同步时偶然发现)
- 最初只管 skills/ → 后来 rules/commands/agents 都要同步 → 全部一起管
- 代码仓库预置版本经常落后 → 加了「全局最新为准」规则
- 团队所有人安装后拿到同一套环境,不会「你那边能跑我这边不行」
- skills 优化后 push,团队跑一次 update 就拿到最新版,零沟通成本
- 每个人通过 /learn 沉淀的经验汇入同一个知识库,14 人的隐性知识变成共享显性资产
dev-team-env-init — 环境一键配置
痛点: 推广时人人问环境、文档散各处、换电脑要重配。
设计: 一个命令跑完,交互式逐项确认,引导配好全套:
| 配置项 | 配什么 |
|---|---|
| Shell alias | claude 快捷命令、工作目录跳转 |
| 环境变量 | API 地址、代理、模型选择 |
| Jira MCP | 问题查询 |
| 飞书 MCP | 文档/消息/多维表格 |
| ADT (IPD) MCP | 问题库查询/创建/评论 |
| GitLab MCP | 代码仓库/MR/Pipeline |
| Gerrit MCP | Code Review |
| GitNexus MCP | 跨仓库源码知识图谱 |
配完后还有一个自检脚本(env-check.sh),跑一下就知道缺什么,标 ✅/❌。新人不用问任何人,跑一次全搞定。
第五步:代码审查也能用同样能力
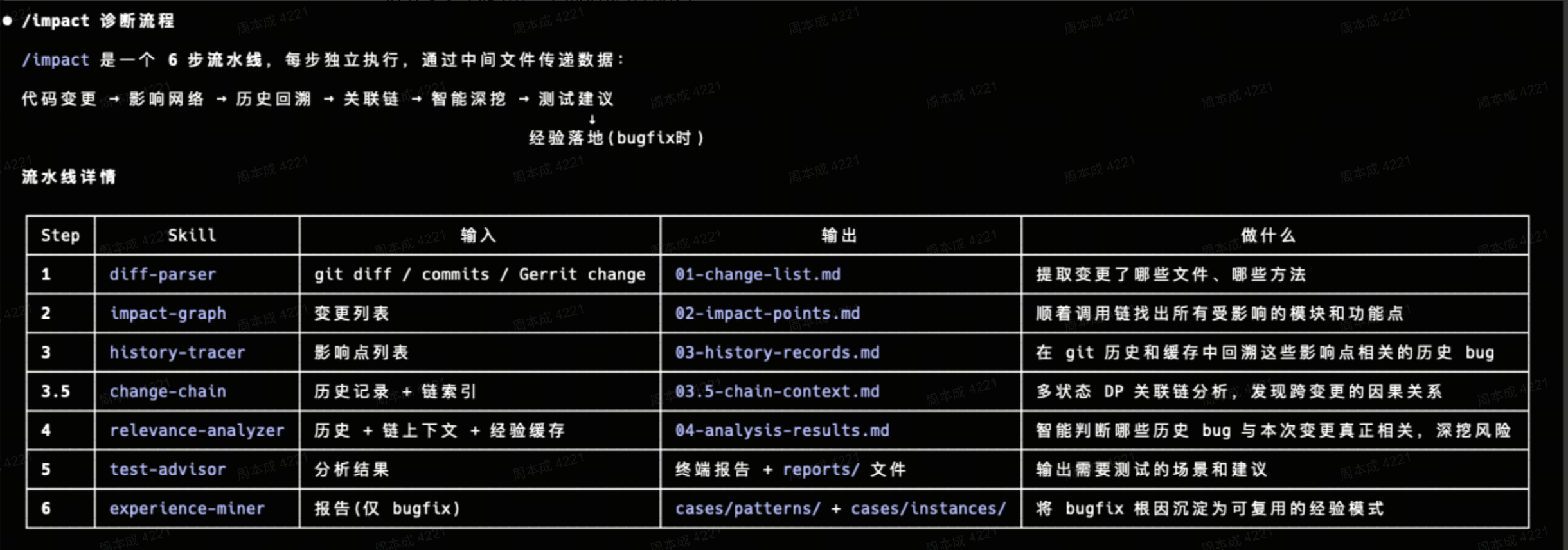
impact-analyzer — 变更影响分析
由来: 年前做了 testcase-derivation(从 Gerrit change 推导测试 case)。做的过程中发现 AI 分析代码变更的影响范围很准——给它一个 diff,它能推出「改了 A 会影响 B 和 C」。
6 步链路:diff解析→影响图→历史追溯→变更链→关联→测试建议。
这个能力本身就很有用(提 change 前知道影响面),但更重要的是它带来了一个认知:AI 分析危险代码很准。
review — 知识增强的代码审查
由来: 有了 impact-analyzer 后发现,既然 AI 能从 diff 推出影响范围,那 review 也可以基于这个能力——先让 impact 圈定哪些代码被影响了,再让 review 只对这些危险代码深入分析。不需要全盘扫。
怎么一步步改进的:
- 最初 os-core-aicr 全盘扫描 → 又慢又泛泛
- 加了 impact-analyzer 先圈影响范围 → review 只在范围内深入 → 快了
- 做 testcase-derivation 训练了「从代码推风险点」的能力 → 反哺 review 更精准
- 接入知识库 → 能引用「这个位置上次出过什么 bug」→ 有了记忆
- 最终:
/review= impact(影响面)+ review(风险判断)+ 知识库(历史经验)
另一个推论: 正向能从代码推风险,逆向给一个 bug 现象也能推哪段代码是根因 → 这就是 unified-diag 的推理能力来源。review 和 diag 共享同一套代码分析能力,只是方向不同。
第六步:人看不过来 → 自动化
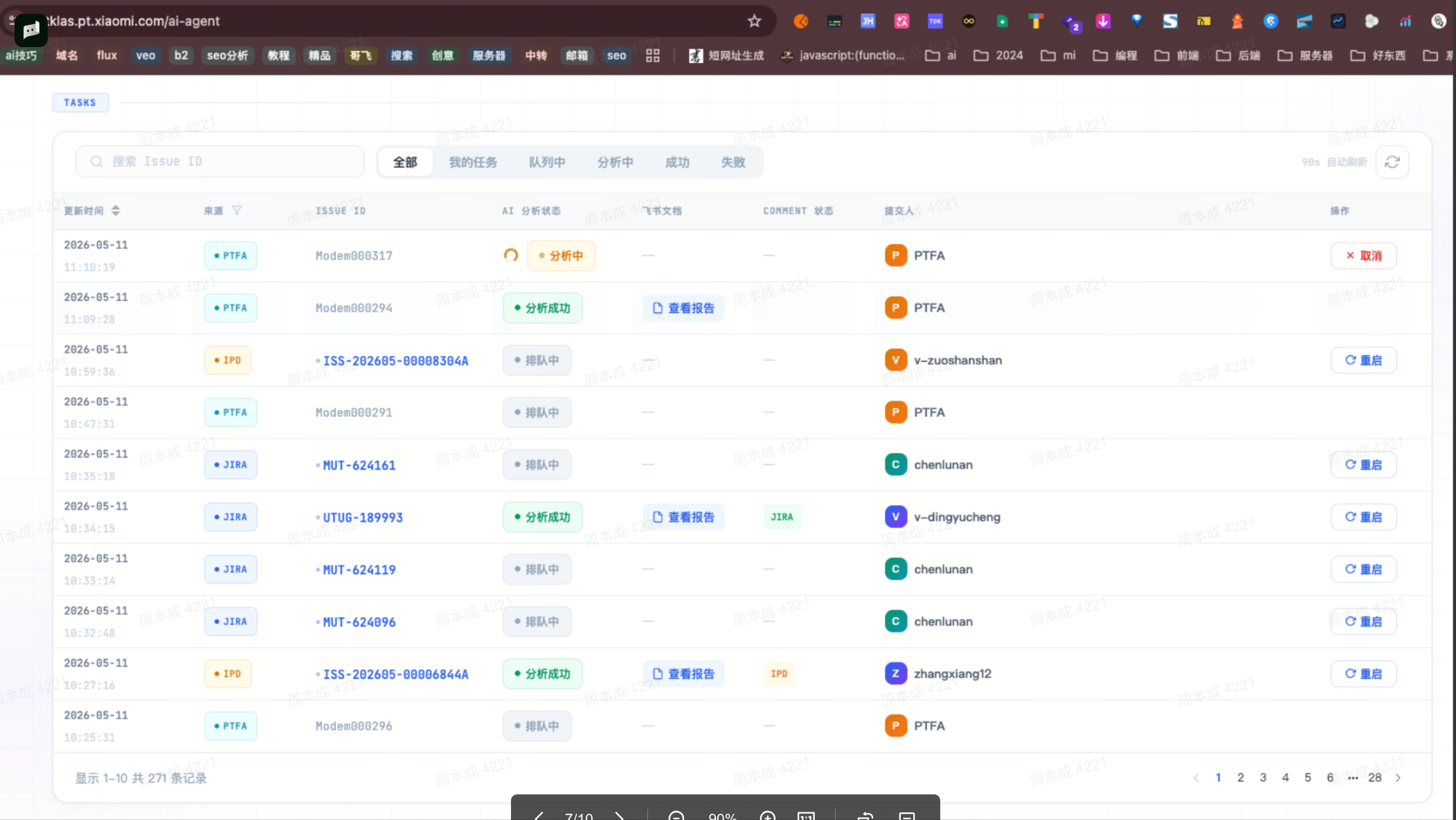
BB-8 / daily-investigate — 全自动诊断
痛点: 每天新问题太多,人工逐个看不完。
核心流程:
白板: BB-8 自动诊断流程
定时任务 9:00/15:00/20:00 ↓ 拉 ADT+Jira 数据 ↓ 按模块过滤目标问题 ↓ 并行派发 Agent 分析 ↙ ↘ 下载 bugreport 代码溯源 ↘ ↙ 日志分析 + 根因定位 ↓ 飞书文档 + ADT 评论 + 平台 POST
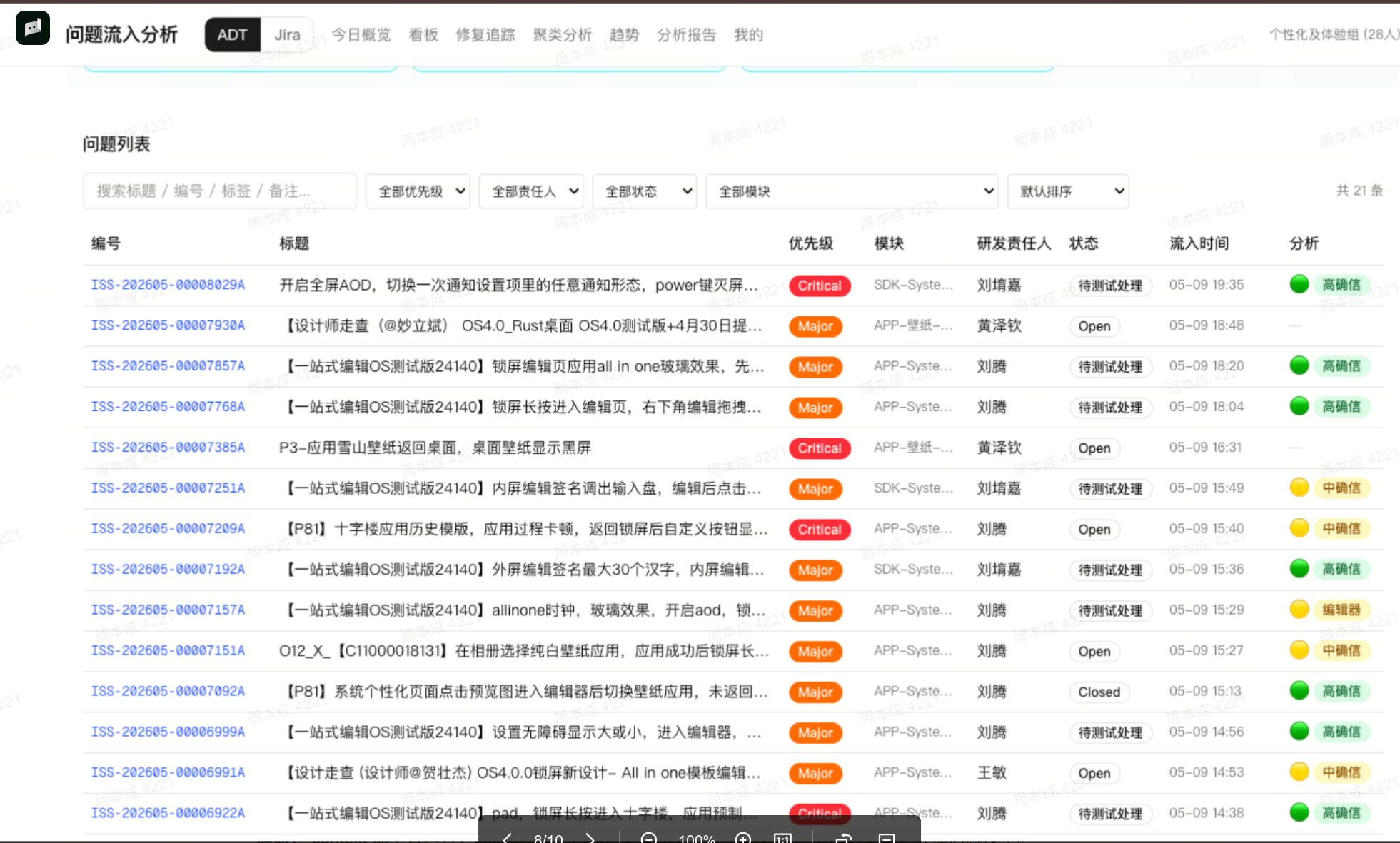
产出:
- 每个问题一份飞书诊断报告(根因 + 代码位置 + 修复建议)
- ADT 评论自动回填(HTML 格式 + 置信度 + 飞书链接)
- issue-analytics 平台实时更新
设计要点:
- Dispatcher 是代码逻辑(确定性),分析是 AI(需要理解力)
- 有 bugreport → 下载分析 → HIGH confidence;无 bugreport → 代码推理 → MEDIUM
- 4 个代码仓库全挂载(common_widgets / MiuiSystemUI / MiuiSystemUIPlugin / MiuiAod)
- Skills 知识库注入,Agent 按 /sz-investigate 15 Phase 流程执行
下一步: 增加 Supervisor 监督角色 — 质检分析结果(铁律检查 + 追问补充),把固定流程(附件下载、输出回填)抽离为确定性步骤,减少 AI 自由发挥的空间,提升稳定性。
远端 7x24 运行。本地搭了 issue-analytics 平台看趋势(Next.js + SQLite)。
第七步:Session 多了管不过来
context-history-finder — 跨 Session 记忆
痛点: context 满了丢内容,session 找不回来。之前的讨论、分析过程、得出的结论,关掉后就没了。
设计: 跨 OpenCode + Claude Code 搜索历史会话,模糊匹配关键词/主题,按内容量+时间排序。解决的是「之前聊过但找不到了」的问题。
warp-claude-manager — 多 Session Dashboard
找到历史会话是一回事,管理当前正在跑的 session 是另一回事。
痛点(原话):
设计演化:
- 最初想法:扫描所有 claude 进程识别在干嘛 → 发现进程信息太少,看不到内容
- 转变思路:不从外部观察,而是让 claude 启动时主动记录自己的状态
- 用 Claude Code 的 hook 机制(SessionStart/Stop/UserPromptSubmit)追踪生命周期:启动→处理中→等待→完成
- 研究 warp 终端发现它的搜索能匹配 tab 名和命令历史 → 给每个 session 写一个唯一 tag 文件
- 最终:hook 记录状态 + tag 匹配 warp 终端 → Dashboard 展示所有 session + 点击跳转回对应终端
核心: context-history-finder 解决「找回过去」,warp-claude-manager 解决「管理现在」。
第八步:怎么保证持续变好
这是整套体系最关键的部分。skills 不是写完就不动了,需要三个机制配合让它持续变好:
/learn — 输入端
每次 /diag 分析完一个问题,AI 走了完整推理过程。关掉 session 这些全丢了。/learn 把分析成果结构化留下来,让下次同类问题不再从零开始。
learn 一次,沉淀的不是一句话笔记,是按 Section 结构化的多维知识:
| Section | 沉淀什么 | 下次怎么用 |
|---|---|---|
| 0. 诊断自评 | 本次分析打分 + 人纠正了哪几步(corrections_log) | 积累后变成 eval 的测试数据和 hint |
| 0.5 诊断报告归档 | 完整的分析过程归档为飞书文档 | 可追溯、可分享、可复盘 |
| 1. 案例(CASE) | 现象→根因→代码路径→验证命令→修复 diff | AI 下次碰到同类现象直接命中方案 |
| 2. 推理规则(inference) | 「看到 XXX 日志 → 大概率是 YYY」的 YAML 规则 | AI 推理时自动适用 |
| 3. 修复方案(fix) | 「这类问题标准修法是在 ZZZ 加判断」的 YAML | AI 给出修复建议而非只定位 |
| 4. 检测规则(DETECT) | 满足条件 A+B+C 时自动报警 | 下次不用人提 bug,AI 主动发现 |
| 5. 架构知识 | 数据流、模块关系、接口约束 | AI 分析时理解系统全貌 |
| 6. 代码路径 + debug 手段 | 关键方法调用链 + 最有效的 logcat 命令 | AI 直接用最短路径定位 |
| 7. 方法论洞察(Insights) | 从单个 bug 提炼的通用模式 | 跨领域复用,其他模块也受益 |
每一个 Section 都是为了让 AI 下次分析同类问题时更强:
- 自评让 AI 知道自己哪里容易错,下次主动避开
- 案例让 AI 不用重新推理,直接给方案
- 推理规则让 AI 看到日志就能判断,不用逐行 trace
- 修复方案让 AI 不只是「找到问题」还能「给出怎么改」
- 检测规则让 AI 主动发现问题,不用等人来报 bug
- 架构知识让 AI 理解上下文,不会建议改 A 结果把 B 搞坏
- 代码路径和 debug 手段让 AI 走最短路径定位,不绕弯
- 方法论让 AI 学会举一反三,一个领域的经验用到其他领域
一次 /learn 触发,AI 自动判断这次分析适合哪几个 Section,全部写入。人只管说一句,结构化和写入都是 AI 的事。
14 个人各自 learn,用户名目录隔离零冲突。一个人的 learn 所有人受益——你沉淀的案例,明天你同事碰到同样问题时 AI 直接调用。
self-evolve — 整理端
learn 进来的越来越多,问题来了:有重复的、有过时的、有矛盾的。靠人审太慢。self-evolve 让 AI 自己做整理和优化。
具体做了什么:
- 发现缺口:AI 诊断时走到某个领域发现没有对应知识 → 提出「allinone-hub 缺少签名竖排 emoji 截断的处理规则,建议补充」
- 合并矛盾:两个人对同一个问题结论不同 → AI 对比后提出「实际是两者叠加,建议合并为一条」
- 标记过时:代码已经重构了,旧案例的路径不存在了 → AI 提出标记
- 蒸馏外部知识:喂给 AI 一篇文章或一个开源项目,它读完后提炼出适合我场景的东西融入现有 skills
怎么吸取经验:
self-evolve 不是凭空优化,它的输入来源有三个:
- 从 contrib 积累中学:14 个人的 learn 内容积累到一定量后,AI 扫描发现 3+ 条相似案例 → 提炼出通用 PATTERN 写入正式知识库。从个例变规律。
- 从 corrections_log 中学:每次 /learn 时记录了「人在第几步纠正了 AI」。积累后 AI 发现某类问题总在同一步走偏 → 调整那个环节的推理规则或优先级。被纠正的地方就是需要改进的地方。
- 从外部资料中学:喂一篇文章、一个别人的 skill、一份开源代码,AI 读完后对比自己当前的做法 → 找到差距 → 提出具体改什么。比如看到 Harness Engineering 文章后,直接产出了 7 条审计规则变成 skill-optimizer。
洞察团队问题模式: 比如 3 个人在不同时间都碰到了「折叠屏 rotation 定义不一致」→ self-evolve 发现这不是个案,是架构层面缺规则 → 写入推理引擎,下次所有人碰到折叠屏方向问题 AI 自动考虑这个差异。
对比分析思路: 同一类问题不同人的排查路径不一样。self-evolve 对比后发现某个人的思路更高效 → 提炼更优路径更新到排查流程里。整个团队的分析路径跟着升级。
最终输出: 不只是「知识库更新了」,而是具体的优化建议:哪条路由规则需要加权重、哪个领域的检测规则缺失、哪个 skill 的分析流程该调整步骤顺序。审批后直接改进 skills,下次所有人用的就是优化后的版本。
skill-optimizer 怎么来的: self-evolve 做着做着发现,优化不只是改知识库内容,skill 本身的结构也有问题——有的写得太长加载慢、有的缺校验步骤、有的子文件没索引。先有了「skill 本身也要优化」的需求,然后看到一篇 Harness Engineering 文章讲 AI skill 的审计原则,让 AI 读完直接蒸馏成 7 条规则做成了 skill-optimizer。顺序是:self-evolve 发现问题 → 外部文章提供方法论 → AI 蒸馏成工具。
unified-diag-eval — 验证端
https://www.iceyao.com.cn/2026/05/03/agent-skills-evals-skill-creator/
self-evolve 改了 skills,怎么知道改好了还是改坏了?没有验证就不敢频繁改。
具体怎么验的:
- 闭卷考试:积累 20 条标准答案(golden set),测试时屏蔽知识库里这条的案例、代码回退到修复前。只给 AI 一句现象,看它能不能独立找到根因
- 两层防作弊:删知识(AI 不能查到答案)+ 删代码修复(AI 不能从 fix 注释反推)
- 四维度打分:路由对不对(25分)+ 根因对不对(40分)+ 效率高不高(20分)+ 方法论规范不规范(15分)
- 退化检测:每次跑完对比上一次,上次通过这次不通过 = 退化,必须归因是 diag 改了还是知识库改了
- 真实数据:某条 case 开卷 95 分、闭卷 45 分——证明 AI 在「背答案」不是「会分析」,这才是真实水平
为什么主管要关心 eval: 如果团队要推广 AI 辅助分析,第一个问题就是「怎么知道 AI 分析得对不对」。eval 给了量化答案——不是感觉好不好,是跑分多少分、比上次高了还是低了。
三者怎么配合
白板: learn / self-evolve / eval 闭环
learn输入 → self-evolve整理+优化 → eval验证 ↙ ↘ 变好→确认发布 退化→回滚+归因 ↓ (反馈回 self-evolve)
learn 负责进,self-evolve 负责理和改,eval 负责验。这三个解决的是同一个问题:怎么让 AI 辅助分析的能力持续变强,而不是写完就不动了。
各 Skill 核心流程速览
| Skill | 核心流程 | 设计特点 |
|---|---|---|
| aar-deploy | 确认目标→编译→部署→提change→验证 | 能自动的自动,关键步骤问人确认 |
| build-pool | acquire slot→编译→release→记历史 | 资源池思维,用完归还,死锁自清 |
| clouddev | 本地编aar→SFTP传→改引用→make→下载APK | 多方案试错后选最稳的 |
| corgi-build | 查分支→组参数→签名→调API→轮询 | 先跑通再补全,每次纠偏一点 |
| allinone-hub | 关键词路由→查案例/架构→输出方案 | 零散skill汇总成统一知识库 |
| unified-diag | 门控→路由→分析→验证→报告→沉淀 | 分层管道,信息不够不让进下层 |
| /learn | 说learn→AI按7维结构化→存contrib/ | 人管说,AI管分类存储 |
| self-evolve | 汇总contrib→发现模式→提建议→审批→改进 | AI主动提出而非被动等人教 |
| eval | 屏蔽知识→从零诊断→对比答案→检测退化 | 裁判选手分离 |
| review | 识别危险代码→深度分析→引用知识库 | 只看高风险的,不全盘扫 |
| BB-8 | 拉issue→过滤→自动分析→回填→沉淀 | 7x24无人值守 |
| warp-claude-manager | hook追踪→tag标识→Dashboard→搜索跳转 | 状态自动同步 |
| setup-shared-skills | git pull→遍历分类→建软链→清死链 | 一个权威源,全局最新为准 |
| impact-analyzer | diff→影响图→历史追溯→关联→测试建议 | 6步链路串联 |
Skills 的四种来源
外部方法论吸收是持续燃料——看到好文章就 /learn 进来。
团队怎么自然跟上来的
- 自己用着顺手 → 同事问「你那个怎么搞的」
- 放到 git 仓库 + 一键安装
/learn门槛够低 → 有人用- 第一个同事贡献 3 个案例 → 验证机制 work
- 陆续 14 人加入
几个踩坑后的认知
| 踩过的坑 | 后来怎么想的 |
|---|---|
| 造了没人用的 skill | 没有痛点的不造 |
| 放代码仓库同步 | skills 节奏跟代码发版不一样 |
| submodule 汇总不了 | 一个权威源 + 软链最简单 |
| 浏览器自动化不稳定 | 翻文档找 CLI 方案 |
| review 全盘扫描慢 | 先识别危险代码再深入 |
| 知识库只增不减 | 需要 self-evolve + eval |
对团队的实际价值
| 维度 | 效果 |
|---|---|
| 编译效率 | 5分钟 → 1句话 |
| 知识流动 | 14人经验不随人走 |
| 新人上手 | 老问题AI给历史方案 |
| 每日issue | BB-8自动先分析 |
| 接入成本 | 一键安装零培训 |
贡献者
| 贡献者 | 提交数 | 方向 |
|---|---|---|
| liuyujia3 | 160 | 架构+基础设施 |
| huanghong3 | 47 | 编辑器+动画+无障碍 |
| chenyangye | 38 | 通知景深+AOD |
| leizhutao | 28 | 十字楼+模板 |
| zhangdian | 19 | 签名+个性化 |
| wangmin23 | 7 | 十字楼动画 |
仓库地址
1. 代码仓库(日常开发用):
git clone "ssh://liuyujia3@git.mioffice.cn:29418/miui/sysui/common_widgets" && (cd "common_widgets" && mkdir -p `git rev-parse --git-dir`/hooks/ && curl -Lo `git rev-parse --git-dir`/hooks/commit-msg https://gerrit.pt.mioffice.cn/tools/hooks/commit-msg && chmod +x `git rev-parse --git-dir`/hooks/commit-msg)2. shared-skills 仓库(AI 能力体系):
git clone git@git.n.xiaomi.com:sz-framework/skills.git ~/.claude/shared-skills
bash ~/.claude/shared-skills/skills/setup-shared-skills/scripts/link-shared-skills.sh装完 shared-skills 后,在 Claude Code 里执行 /setup-shared-skills 完成软链建立和全局生效。后续更新也是同一条命令。AI 也能帮你拉代码——说「拉 common_widgets 最新代码」它会自动处理 clone/fetch/checkout。不用记仓库地址和 hook 命令。
后续想做的
eval golden set 扩充到按领域各 20 条✅ 已完成 20 条(6 领域覆盖)learn 时自动评估本次分析质量✅ 已完成(corrections_log + 11 维度自评)unified-diag 加版本号✅ 已完成(v1.4@git_hash 双版本追踪)- Level 2 闭卷全量跑(20 条 code reset,当前只跑了样本)
- 从 corrections_log 自动生成 hint 字段(当前手动填)
- eval agent 分析完后也 /learn(错误模式沉淀)
- 探索复制到其他团队的可能性
拉代码跑起来
# 1. 克隆代码仓库(以 common_widgets 为例)
git clone "ssh://liuyujia3@git.mioffice.cn:29418/miui/sysui/common_widgets" && (cd "common_widgets" && mkdir -p `git rev-parse --git-dir`/hooks/ && curl -Lo `git rev-parse --git-dir`/hooks/commit-msg https://gerrit.pt.mioffice.cn/tools/hooks/commit-msg && chmod +x `git rev-parse --git-dir`/hooks/commit-msg)
# 2. 进入目录启动 Claude Code
cd common_widgets
claude
/setup-shared-skills# 3. 安装 shared skills(可选,获得团队全套 135 个 skill)
git clone git@git.n.xiaomi.com:sz-framework/skills.git ~/.claude/shared-skills
bash ~/.claude/shared-skills/skills/setup-shared-skills/scripts/link-shared-skills.sh